
Announcement FAQs
OpenAI has acquired Rockset. You can read more about it here .
Will this interrupt my application built on Rockset?
There will be no immediate service disruption for paid customers. See the question How long will the service remain available? below regarding timelines.
Do I need to move my application off Rockset onto a new platform?
Yes, you will need to eventually move your workloads from Rockset onto a new platform. You will continue to have access to our support team who is available to assist as much as they can by providing the necessary resources, support and guidance during this transition.
Our support team is available Monday through Friday, from 7 AM to 5 PM PDT. Please reach out to them via a support ticket or email us at [email protected].
How long will service remain available?
Customers paying month-to-month or in arrears will have until Monday, September 30th, 2024, 5 PM PDT to off-board.
If you are a contracted customer, please work with your Rockset account team who will be reaching out to develop and implement an offboarding plan that suits your needs.
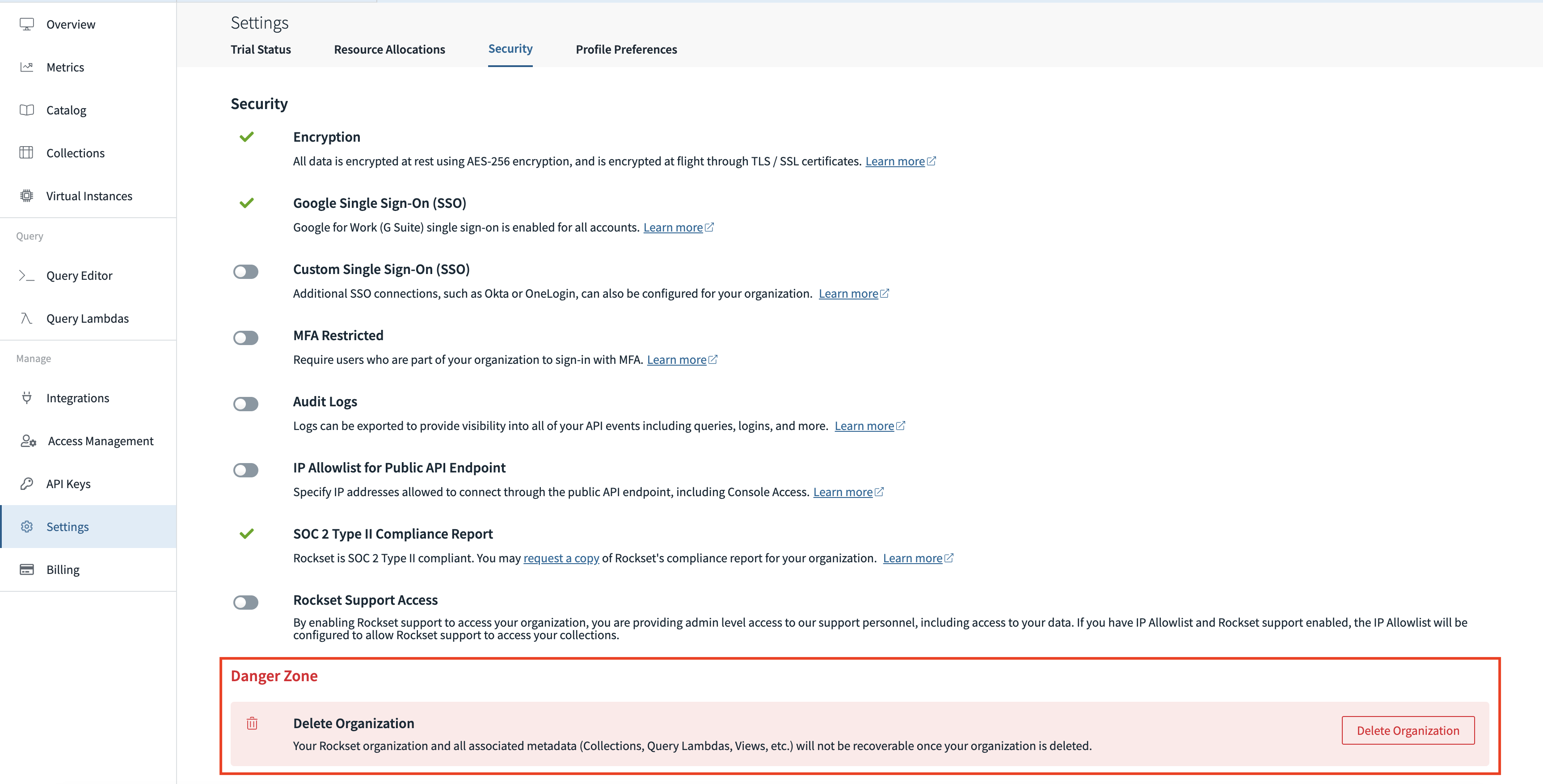
How can I delete all my data off Rockset / delete my Rockset account?
Only an admin user can delete your Rockset organization using the Delete Organization button in the Settings > Security tab of the Rockset console. Deleting your organization is an irreversible action and will delete all associated data and metadata.
I currently have a trial account. Can I still become a paid customer?
No, existing trial users cannot become paid users.
Can I start a new Rockset trial?
No new Rockset trials or accounts can be created going forward.
Will customer support be available?
Yes, Rockset customer support will be available Monday - Friday, 7am - 5pm PDT (San Francisco time). You can reach support via email at [email protected] or via a support ticket.
Will there be more resources to help with the process of moving off Rockset?
Yes, our team is actively working on more resources for moving off Rockset that will be made publicly available. We have a dedicated support team that will be working with customers to ensure a smooth and successful transition. We will be sharing best practices, alternate solutions, automation scripts, and more as we work with our customers to best understand their off-boarding needs. We will update our documentation with these resources as they become available.
Updated 9 months ago