
Ingest Performance
This section highlights the best practices for ingest performance. Ingest Performance refers to throughput and latency of data being ingested into Rockset. Throughput measures the rate at which data is processed, impacting the database's ability to efficiently support high-velocity data streams. Data Latency, on the other hand, refers to the amount of time it takes to ingest and index the data and make it available for querying, affecting the ability of a database to provide up-to-date results.
Virtual Instance Sizing
Rockset offers different Virtual Instance sizes. It is important to size the instance correctly to handle the ingest workload for your production applications. Refer here for the peak streaming ingest limits for each Virtual Instance offering.
If the Virtual Instance is under sized for your workload, the streaming ingest latency will increase for managed sources. For Write API, this means that the client will receive "Too Many Requests (429)" error.
Data Schema and Configurations
Source and Collection configurations such as average document size, deeply nested objects and arrays, Ingest Transformations, and clustering may lead to different observed throughputs.
If your data contains deeply nested objects and arrays which are not needed for querying, you can configure to drop them using Ingest Transformations or use _stored to exclude such fields from inverted and range indices.
Virtual Instance Compute Contention
Virtual Instances's resources are shared between ingest and queries. Multiple Virtual Instances allow you to isolate and independently scale compute for ingest and queries.
Compute Contention Tip
To eliminate the problem of compute contention, we recommend using one Virtual Instance for handling all the streaming ingest workload exclusively (with no query requests routed to that Virtual Instance, sometimes referred to as an “Ingest VI”), and additional Virtual Instances for each query use case.
Source Configurations
Each managed source has different characteristics which can affect ingest performance. For best practices on configuring your source, refer to the respective data sources page.
Dedicated Streaming Ingest
By enabling Dedicated Streaming Ingest, infrastructure and settings are configured to deliver the best performance for your latency sensitive ingest operations. When this feature is enabled:
- Dedicated resources are provisioned for tailer operations directed onto your default VI.
- Batch sizes and buffer flush times are configured for low-latency.
Why Dedicated Streaming Ingest?
Dedicated Streaming Ingest is designed to support ingest latency sensitive use cases. Dedicating an isolated set of compute resources for your tailer activities creates an environment conducive to a low and stable ingest latency. The various batch and flush settings are tuned to achieve a consistently lower median latency.
Non-dedicated streaming ingest has been designed to provide the lowest average latencies at an optimal price point. It is subject to tailer autoscaling activities which may result in observable increases in latencies exceeding the 90th percentile. When Dedicated Streaming ingest is enabled, a fixed number of resources are provisioned proportional to your VI size which are not subject to auto-scaling activities.
If your use case requires consistently lower ingest latencies, Dedicated Streaming Ingest is recommended.
Toggling Dedicated Streaming Ingest
REST API
On your default VI, you can enable dedicated streaming ingest via the Update Virtual Instance endpoint. Sending a request with the following payload will enable dedicated streaming ingest:
$ curl --request POST \
--url https://api.{region}.rockset.com/v1/orgs/self/virtualinstances/{defaultViId} \
-H 'Authorization: ApiKey {yourAPIKey}' \
-H 'Content-Type: application/json' \
-d '{
"enable_dedicated_streaming_ingest": true
}'
After sending the request to enable Dedicated Streaming Ingest, there will be a brief scaling period which occurs while your resources are provisioned. Under typical operating conditions, the scaling duration should be a few minutes. During this time, VI resizing will be blocked. To know when Dedicated Streaming ingest is enabled and resources are provisioned, query the VI using the Retrieve Virtual Instance endpoint. The dedicated_streaming_ingest_active field is true when your dedicated streaming resources are provisioned and ready for processing ingest activity.
$ curl --request GET \
--url https://api.{region}.rockset.com/v1/orgs/self/virtualinstances/{defaultViId} \
-H 'Authorization: ApiKey {yourAPIKey}'
...
{
"data": {
"name": "main",
"created_at": "2022-07-05T21:21:20Z",
"state": "ACTIVE",
"current_type": "SMALL",
...
"enable_dedicated_streaming_ingest": true,
"dedicated_streaming_ingest_active": true
}
}
Console
From the Virtual Instance tab of the Rockset Console, Dedicated Streaming Ingest can be toggled.
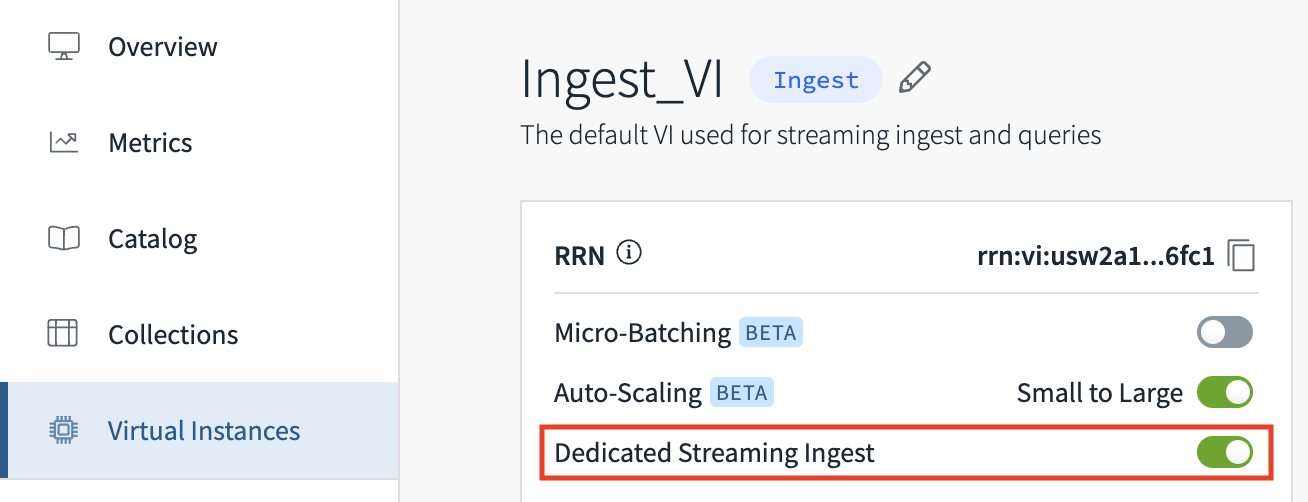
- There is currently a default limit of 10 toggle events per day.
- If you have a legacy MongoDB integration configured with static IP addresses, you will not get the full isolation benefits for sources using that integration. To receive the full benefits configure your integration with Atlas Privatelink
Micro-Batching
Micro-Batching is a configuration that can be enabled for your ingest Virtual Instance. When Micro-Batching is enabled, your Virtual Instance will automatically suspend when your ingest has “caught up” (i.e. when ingest latency is near zero) and resume on a specified interval. You may also have an active query Virtual Instance that allows you to serve a query workload on mounted collections, even while your ingest Virtual Instance is suspended.
Enabling Micro-Batching allows you to maximize cost efficiency and performance of Rockset by trading off cost with ingest latency. Suspended Virtual Instances do not incur compute costs.
See more details about Micro-Batching here.
Updated 10 months ago