
Query Performance
Rockset enables you to run SQL on your semi-structured data and get results in milliseconds without having to worry about data modeling or indexing. To make this possible, Rockset has built most of its database components from the ground up, including the compiler, planner, optimizer, indexing engine, and execution engine.
Rockset's current optimizer uses a set of heuristics to estimate the optimal execution plan, but sometimes these heuristics may not be optimal, given your data distribution. In these cases, you can leverage optimizer hints to gain significant performance improvements. Failing to provide these hints can increase your query latency by orders of magnitude. For example, choosing the wrong order for a series of joins, the wrong index to use for a particular Collection, or the wrong join strategy are some of the common missteps.
This topic provides you tools to avoid the common missteps and write queries that unlock the full performance potential of Rockset's schemaless design.
Index Optimizations
All data that comes into Rockset is indexed in three ways:
Row Index
In the row index, values for all fields in the same document are stored contiguously. This lets you efficiently retrieve all fields for a particular document (i.e., SELECT *). You cannot force a query to use this index since it is much slower for anything other than SELECT *.
Columnar Index
In the columnar index, all values for the same field across all documents are stored contiguously. This lets you efficiently retrieve all values for a particular field. For example, SELECT AVG(a) FROM foo. You can force the use of the column index by adding HINT(access_path=column_scan) immediately after the collection name.
Search Index
In the search index, records are sorted by field and value, so all values for a field that are equal are stored contiguously. This lets you efficiently retrieve documents where a field has a particular value. For example, SELECT COUNT(*) FROM foo WHERE a = 5. You can force the use of the search index by adding HINT(access_path=index_filter) immediately after the collection name.
There is also a variation of this hint that can be used for range queries where you want the result sorted by a particular field. For that case, add HINT(access_path=index_scan, index_scan_sort_field=XYZ) and substitute XYZ as appropriate. This may be helpful if you want the final output sorted by the field with the filter.
The search index is always used if there is an indexable term in the WHERE clause of a query. If the WHERE clause is not very selective, you will likely achieve better performance by using the column index in your query. You can force the use of the column index by adding HINT(access_path=column_scan) immediately after the collection name.
In addition, the special field _event_time is optimized differently in the search index. Querying this field is more performant than querying regular fields.
To learn more about how our indexing works, check out our blog on Converged Indexing.
SQL Join Optimizations
Rockset’s SQL engine supports the four kinds of joins listed below.
Hash Join
This is the default and is usually the best join strategy. With hash join, A INNER JOIN B ON A.x = B.x the server will construct a hash set on the values of B.x (which come from the leaves) and then stream the values of A (from another set of leaves) and emit those records for which A.x is in the hash set. This means that the entire collection B must fit in memory.
For equality joins like this one, the work can be distributed across many servers. With N servers, Rockset sends each B.x to server number hash(B.x) % N. Similarly, the values of A.x are sent to the appropriate server. In this way, each hash table constructed by the servers is only sizeOf(B) / N in size. This number N is called the aggregator parallelism, and it is set based on your Rockset Virtual Instance (free, shared, L, XL, 2XL, etc).
Right outer joins are internally converted to left outer joins.
The same logic for equality joins applies to left outer joins, so
A LEFT JOIN Bwill still build a hash set onBand stream the values ofA. However right outer joins are internally converted to left outer joins, soA RIGHT JOIN Bis internally rewritten toB LEFT JOIN A, and in this case, a hash set is built on top ofA, andBis streamed.
A hash join can be forced by adding HINT(join_strategy=hash) immediately after the ON clause (for example, A INNER JOIN B ON A.x = B.x HINT(join_strategy=hash)). Keep in mind that hash join is the default, so this hint is a no-op.
Nested Loop Join
Nested loop join is a slower, less memory-intensive join strategy that closely follows the programming paradigm of a nested loop.
for a in A
for b in B
if a.x == b.x
emit (a, b)
Due to this N^2 behavior, nested loop joins are usually undesirable. However, it can handle arbitrarily large collections without worrying about fitting them into memory. As with a hash join, equality nested loop joins can be distributed across many servers, up to your account’s aggregator parallelism limit.
A nested loop join can be forced by adding HINT(join_strategy=nested_loops) immediately after the ON clause of the join.
Broadcast Join
With broadcast join, A INNER JOIN B ON A.x = B.x will send (or broadcast) the values of B.xto all the leaves that serve shards of collection A. Each of these leaves will then locally perform a hash join by constructing a hash set on B.x and will stream its local portion of collection A to perform the join and forward the results. This can be helpful if collection A is significantly larger than collection B and the join is selective, as this avoids a significant amount of network overhead from transferring all the records of A.
A broadcast join can be forced by adding HINT(join_broadcast=true) immediately after the ON clause of the join.
The Broadcast Join hint is different than the others because the decision to broadcast the join is independent from the strategy.
For example, you could set the join strategy to use nested loops and also enable broadcast. However, broadcast will only be helpful when the collection being broadcasted is small, in which case using the default hash join strategy is best.
Lookup Join
Lookup join is also a leaf-side join, but instead of constructing a hash set on B and performing the join, it looks up the values of B directly in the search index. Lookup joins are only applicable when using equality joins on one field and are only a good idea if there is a very small number of rows in B.
For example, consider the join A INNER JOIN B ON A.x = B.x WHERE B.y = 5. If the predicate B.y = 5 is highly selective and causes the right side of the join to contain only a few (< 100) rows, then it's probably more effective to use a lookup join. Then, the ~100 values of B.x will be transferred to the leaves serving the shards of collection A. For each of those values, Rockset will perform an efficient lookup for whether a matching A.x exists using the search index, and if so, emit a match for further processing or returning of the results.
You can force the use of a lookup join by adding HINT(join_strategy=lookup) immediately after the ON clause of the join.
Data Clustering
During collection creation, you can optionally specify a clustering scheme for the columnar index to optimize specific query patterns. When configured, documents with the same clustering field values are stored together on storage. This makes queries that have predicates on the clustering fields much faster since the execution engine can intelligently avoid scanning clusters that it knows do not match the predicates provided rather than having to scan the entire collection.
To configure clustering for a collection, you need to specify the CLUSTER BY clause in the collection's Ingest Transformation. For example,
SELECT email, country, occupation, age, income
FROM _input
CLUSTER BY country, occupation
This configures the collection with clustering on (country, occupation). Then for example, the query:
SELECT AVG(income)
FROM salaries
WHERE country = 'US' AND occupation = 'Software Engineer'
- Without clustering, the execution engine might perform a scan of the entire collection using the columnar index, followed by a filter for each predicate.
- With clustering, the execution engine will perform a sequential scan on only the cluster corresponding to (
country='US',occupation='Software Engineer'), which will be significantly faster than having to scan the entire collection. Even if the query predicates only match a subset of the clustering fields, the execution engine will still save execution time by scanning only the appropriate clusters. This makes the query run faster and use less CPU. - Usually it’s the queries with predicates on a clustering field and overall selectivity > 2% that can benefit from clustering. If the selectivity is small, we dynamically choose index filter since we see it as search optimized query. Clustering only benefits scan optimized queries.
Predicates that match prefixes of the clustering key will lead to larger improvements during query execution.
In the above example, predicates on
countryor on bothcountryandoccupationwill be more efficient than predicates just onoccupation. Therefore the order of fields that appear in theCLUSTER BYclause are important and should be chosen with your intended query workload in mind.
General SQL Guidelines & Tips
Understanding Execution Strategy
Using EXPLAIN
Rockset's backend supports the command EXPLAIN, that prints out the execution strategy for a query in human-readable text. You can take any query and preface it with EXPLAIN in the query editor console to see this. For example:
EXPLAIN SELECT COUNT(*)
FROM A INNER JOIN B ON A.x = B.x
WHERE B.x = 5;
This example uses the search index on collection B and looks for rows where field x equals 5. It uses the columnar index on collection A, and performs a hash join on them, followed by an aggregation. EXPLAIN can be useful as you try to understand what is happening under the hood, and add hints to get more performance out of the system.
The following example shows what happens when a couple of hints are added:
EXPLAIN SELECT COUNT(*)
FROM A INNER JOIN B HINT(access_path=column_scan) ON A.x = B.x HINT(join_broadcast=true)
WHERE B.x = 5;
Now the query scans collection B using the column index and broadcasts it during the join.
This is just an example of how to apply hints, not necessarily an appropriate example of when you should apply them.
Using the Query Profiler
After running a query in the Rockset Query Editor, Rockset generates a visualization of the query execution profile, which you can see if you click "Query Profiler" on the right.
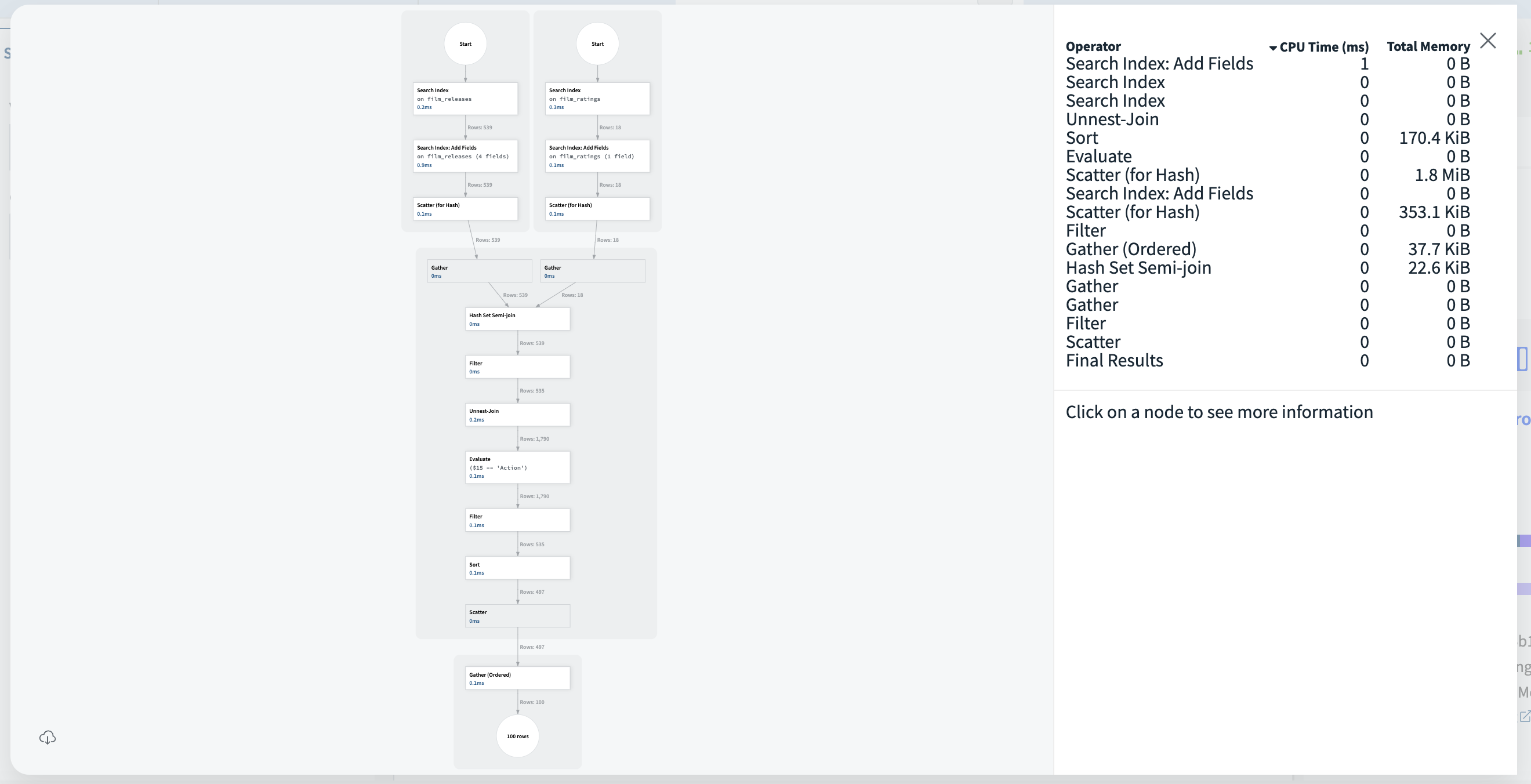
In addition to visually mapping the execution strategy, the Query Profiler shows stats on how much CPU time and Memory each Operator used. The following profile is of the sample query from the Quickstart guide.
Duplicating Predicates
Manually push down and duplicate predicates as much as possible. Apply additional or more selective predicates to collections, to stream less data and provide much faster execution overall. While this is also valid in any SQL system, due to the nature of the RBO, you may also need to explicitly duplicate some predicates where logically applicable.
For example, the following query:
SELECT COUNT(*)
FROM A INNER JOIN B ON A.x = B.x
WHERE B.x = 5
logically imposes a filter on A.x = 5 as well, so that can be added in:
SELECT COUNT(*)
FROM A INNER JOIN B ON A.x = B.x
WHERE B.x = 5 AND A.x = 5
Selecting Join Strategies
Determine which join strategy makes most sense. The default is a hash join and this is usually a good choice, but if the collections are too large to store in memory then consider a nested loop join. If one collection is significantly smaller than the other (after applying predicates from the WHERE clause) consider a broadcast or lookup join.
Hash Join Ordering
When using a hash join, determine whether there may be a better join order. Your query will run out of memory and return an error, if the side of the join where the hash table is being built on (right side for all joins except right outer joins since it’s rewritten) is larger than your query memory limit * aggregator parallelism (both of which are account limits based on your tier). A good rule of thumb is to put smaller collections on the right side of the join. If there are a series of joins in a row (i.e., A INNER JOIN B ON ... INNER JOIN C ON .... INNER JOIN D ON ...) it’s generally best to put the largest ones first so they can be filtered down during the (hopefully selective) join.
Overriding Access Paths
Determine if the access path being used is ideal. The only time you should really have to override this is if you have a non-selective predicate on a huge table. For example WHERE A.x > 0 is probably not selective and if A is huge, the default access path of index filter will be much slower than a column scan followed by a filter step. In that case, execute the following query:
SELECT COUNT(*)
FROM A HINT(access_path=column_scan, data_scan_batch_size=30000)
WHERE A.x > 0
NULL Operators
When using WHERE foo IS NULL, consider using WHERE foo IS NULL AND foo IS NOT UNDEFINED to achieve better performance. A query with WHERE foo IS NULL will return documents where foo is present and set to NULL, and where foo is not present at all (UNDEFINED). If you know there aren't any undefined values or if you aren't interested in them, using WHERE foo IS NULL AND foo IS NOT UNDEFINED will result in a much faster query.
SELECT *
FROM A
WHERE A.x IS NULL AND A.x IS NOT UNDEFINED
Updated 12 months ago