
PostgreSQL
This page covers how to use a PostgreSQL table as a data source in Rockset.
These step-by-step instructions will allow you to migrate your data from your PostgreSQL database table(s) into Rockset collection(s) by using AWS’s Data Migration Service (DMS) to export your data to a target AWS Kinesis stream. Those Rockset collection(s) will stay in sync with your PostgreSQL databases table(s) as they are updated in real-time by reading PostgreSQL CDC streams. This includes:
- Setting up your PostgreSQL Database
- Setting up a target AWS Kinesis Stream
- Setting up an AWS DMS Replication Instance and Migration Task
- Creating an Amazon Kinesis integration
These instructions will work with all of the following PostgreSQL and PostgreSQL-compatible databases:
- On-Premise PostgreSQL (version 9.4 and later for versions 9.x, 10.x, 11.x, and 12.x)
- Amazon EC2 PostgreSQL (version 9.4 and later for versions 9.x, 10.x, 11.x, and 12.x)
- Amazon RDS PostgreSQL (version 9.4 and later for versions 9.x, 10.x, 11.x, and 12.x)
- Amazon Aurora PostgreSQL (refer to the AWS docs for Amazon Aurora PostgreSQL version compatibility)
Step 1: PostgreSQL Database Configuration
For this step, there may be additional configuration steps required if you are using a self-managed version of PostgreSQL (including both on-prem PostgreSQL and Amazon EC2 PostgreSQL). You can read more about setting up a self-managed PostgreSQL database here.
[Optional] Step 1.1 - Create a PostgreSQL user to allow DMS to access your data
We recommend that you use the master user account when designating a PostgreSQL user for AWS DMS to export your data. If you choose not to use the master account, you will need to create a new user with the proper roles and as well as several additional associated objects. You can read more about creating a new PostgreSQL user for AWS DMS here.
Step 1.2 - Configure your PostgreSQL database to emit a CDC stream
AWS DMS supports CDC on Amazon RDS PostgreSQL databases when the DB instance is configured to use logical replication. Note that you cannot use RDS PostgreSQL read replicas for CDC (ongoing replication). A PostgreSQL database’s configuration is encapsulated in the form of a Parameter-Group.
You have to first enable PostgreSQL logical replication to be exposed in the row format by updating the rds.logical_replication parameter, if not yet set, in the corresponding Parameter-Group. The value of this parameter should be set to 1.
In order to do that, you must enable pglogical for Postgres integration. Follow the steps below to create a pglogical extension on your source PostgreSQL database:
- Set the correct parameter:
- For self-managed PostgreSQL databases, set the database
parametershared_preload_libraries= 'pglogical'. - For PostgreSQL on Amazon RDS and Amazon Aurora PostgreSQL-Compatible Edition databases, set the
parametershared_preload_librariestopglogicalin the same RDS parameter group. See Using a PostgreSQL database as an AWS DMS source for additional information.
- For self-managed PostgreSQL databases, set the database
- Restart your PostgreSQL source database.
The rds.logical_replication parameter is static and requires a reboot of the DB instance to take effect. As part of applying this parameter, AWS DMS sets the wal_level, max_wal_senders, max_replication_slots, and max_connections parameters. These parameter changes can increase write ahead log (WAL) generation, so only set rds.logical_replication when you use logical replication slots.
Use the AWS Console to access your PostgreSQL database instance. With each database, you access the associated Parameter Group as shown below:
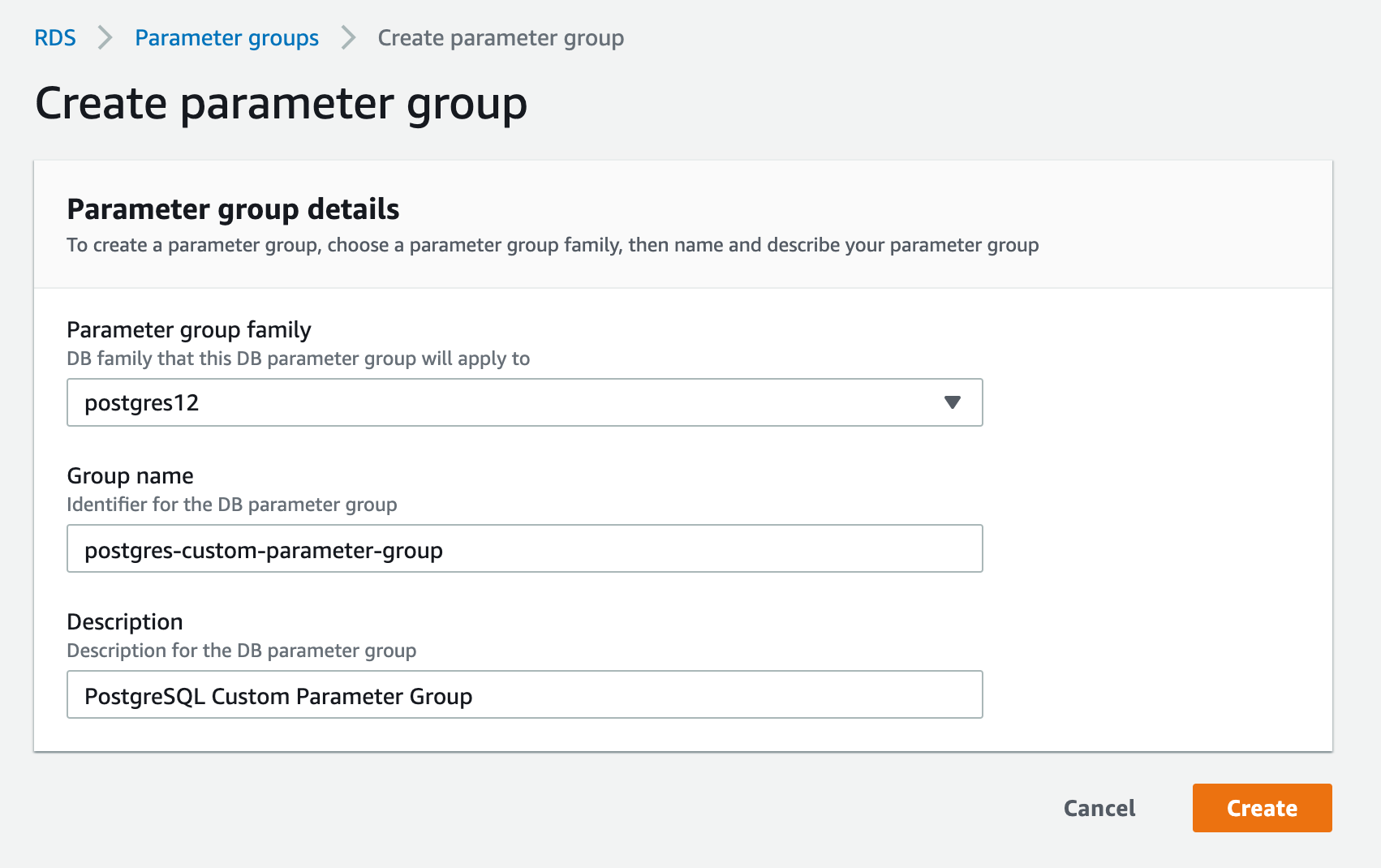
If your PostgreSQL database is using the default Parameter Group, then you will not be able to change that specific parameter in that Parameter Group because the default Parameter Group is read-only. In that case, create a new Parameter Group and then update the rds.logical_replication as shown below:

Step 1.3 - Enable Periodic Backups of PostgreSQL
PostgreSQL binlogs are enabled only if you enable the Periodic Backup feature of PostgreSQL. Select the PostgreSQL instance in the AWS Console and navigate to the Maintenance and Backups tab. If automatic backups are not enabled, modify the PostgreSQL instance to enable the feature. After you are done, the Maintenance and Backups tab should look something like this:

Step 2: Setup your AWS Kinesis Streams
The AWS Kinesis Stream is the destination that DMS uses as the target of a migration job. We will create an individual migration task for each PostgreSQL table you wish to connect with Rockset. Use the AWS Console as shown below to create an AWS Kinesis Data Stream.
It is recommended to use a separate Kinesis Data Stream for every database table you wish to connect with Rockset. See Best Practices for more information.
Step 2.1 Create an AWS Kinesis Stream
Create an AWS Kinesis Stream here.
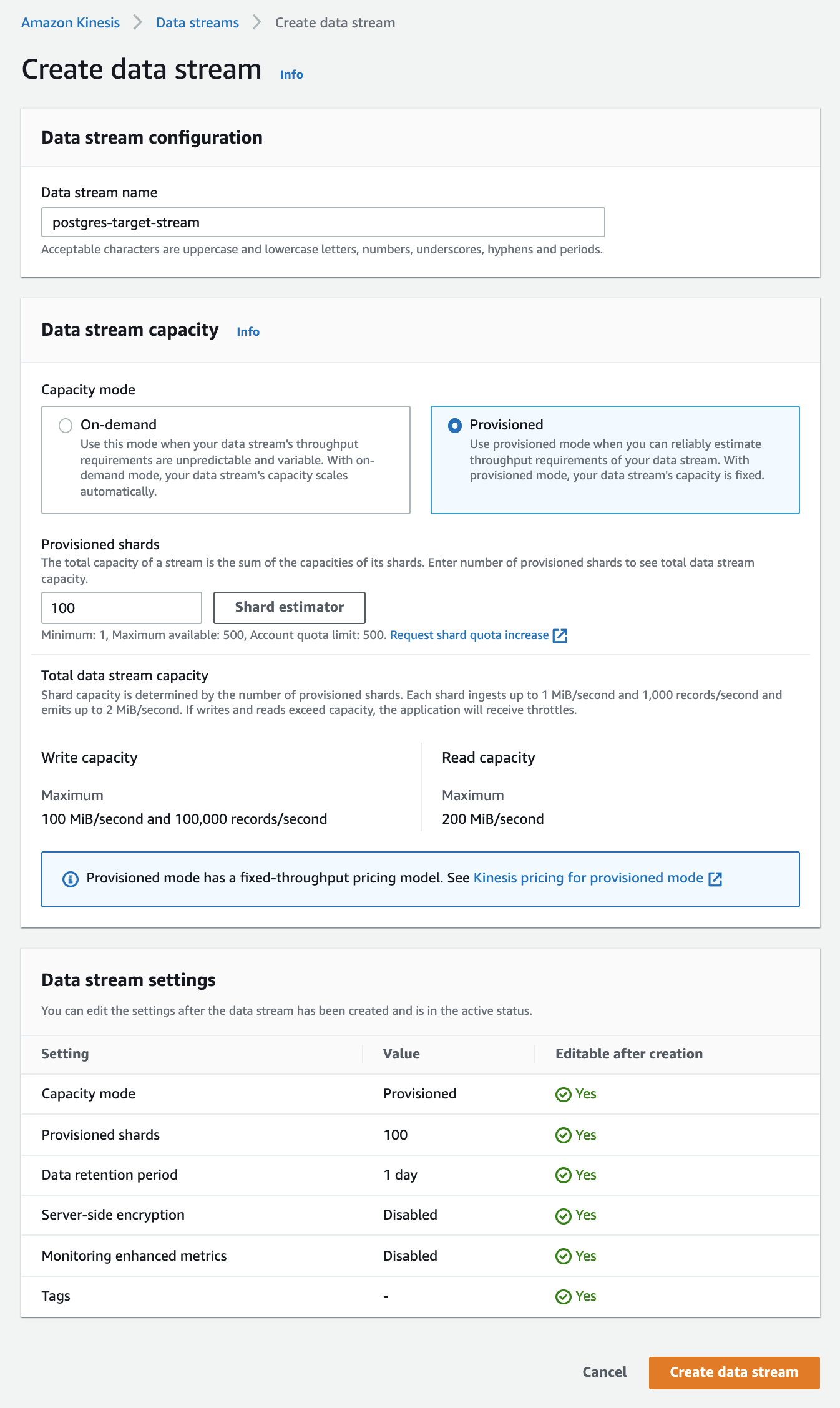
If you select the Provisioned data stream capacity mode, choose a shard count that aligns with the maximum ingest rate of your Virtual Instance size. See Virtual Instances for information on Virtual Instance ingest rates and sizing. AWS Kinesis Shard limits can be found here. If you are not able to estimate the number of shards to configure here, please contact your Rockset solutions architect or customer support.
If you select the On-demand data stream capacity mode, Rockset will dynamically adjust ingest rate to match the number of shards, up to your Virtual Instance ingest rate limit.
Step 2.2 Create a Role for AWS Kinesis Stream
You will need to create a role that has the correct PutRecord, PutRecords, and DescribeStream permissions to access Kinesis. To create this role, please follow these instructions.
Step 3: Setup your AWS Data Migration (DMS)
AWS DMS setup is a multi-step process. First, you have to create one or more DMS Replication Instances. Each Replication Instance comes with a set of resources that power the data migration from PostgreSQL to Kinesis. Then you will create a DMS Source Endpoint for each PostgreSQL database. You will then create one DMS Destination Endpoint for each of the PostgreSQL database table that you want to connect with Rockset. The Source Endpoint is used to configure the name of the PostgreSQL database and the Destination Endpoint specifies the name of the corresponding Kinesis stream. Finally, you will configure a Database Migration Task that specifies the PostgreSQL table names that you want to connect with Rockset. The creation of a Database Migration Task actually starts the migration of data from a specific PostgreSQL table to the corresponding Kinesis stream.
Step 3.1 Create a DMS Replication Instance
AWS DMS uses a replication instance to connect to your source data store, read the source data, and format the data for consumption by the target data store. A replication instance also loads the data into the target data store. Most of this processing happens in memory; however, large transactions might require some buffering on disk. Cached transactions and log files are also written to disk. You can create a Replication Instance by using the AWS Console as follows:
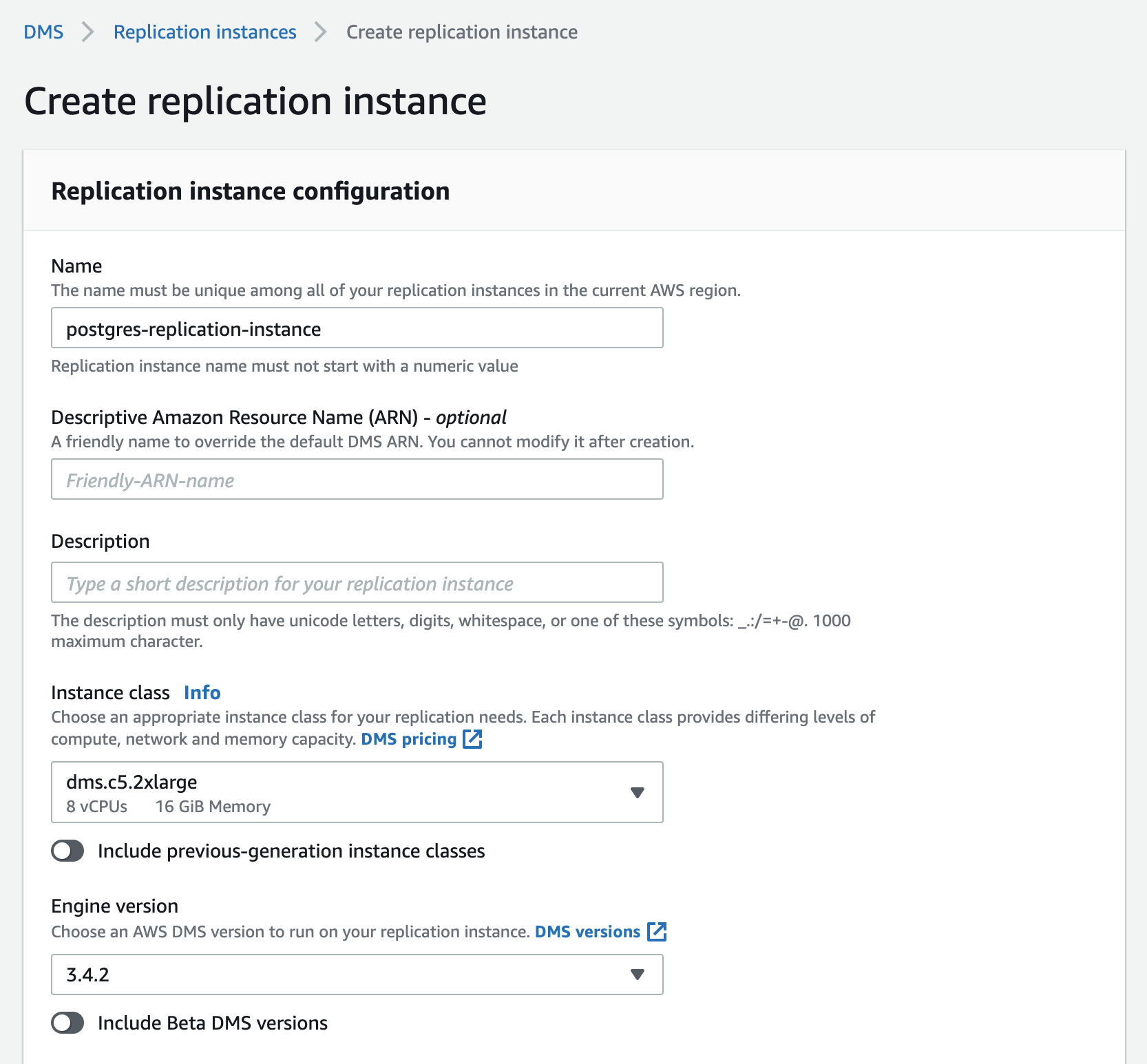
The Instance class specifies the amount of resources provisioned for this replication instance. You can pick the Instance class based on the total amount of data to be migrated and how quickly you want the replication process to occur, although we recommend an Instance class of dms.c5.2xlarge or larger to ensure optimal performance during data ingest. While all versions of DMS Replication Instances should theoretically work for this process, we recommend using versions 3.4.7 or earlier as some recent versions may be occassionally unstable when tailing CDC streams. Name the replication instance appropriately, especially if you are creating multiple replication instances.
Step 3.2 Create a DMS Source Endpoint for your PostgreSQL database
A Source Endpoint specifies the location and access information of your PostgreSQL database. You use the AWS Console to create a DMS Source Endpoint as follows:
- Pick the RDS instance name for the PostgreSQL database.
- Pick an appropriate name for this Endpoint. You can specify access parameters by clicking on
“Provide access information manually", and entering the name database name and port of the
PostgreSQL database. You can use the PostgreSQL useraws-dmsand password that you had created in Step 1.1.
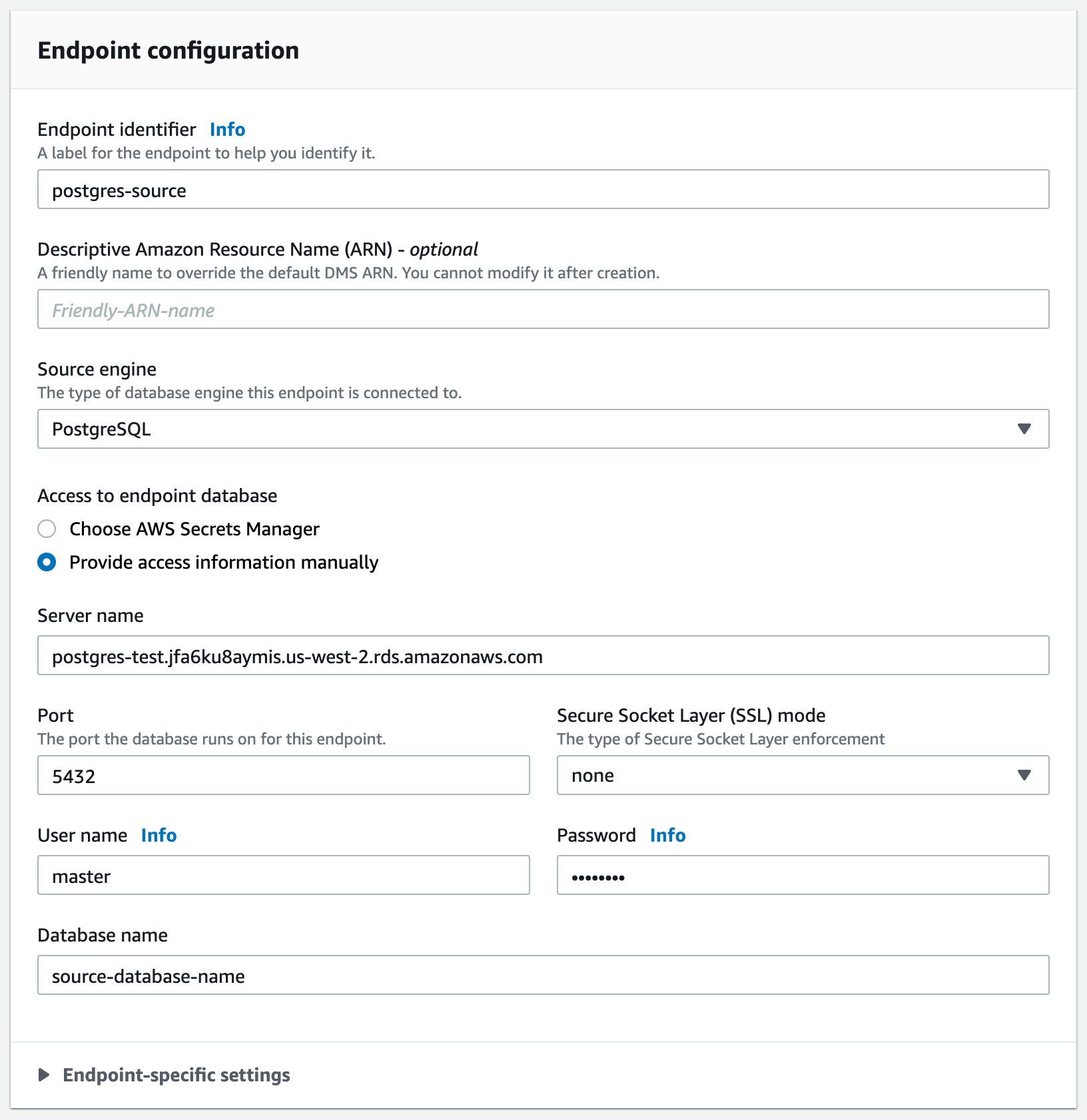
If you want multiple PostgreSQL database tables in a single PostgreSQL database to be connected to Rockset, you only need to create a single Source Endpoint for that database. The same Source Endpoint can then be used by multiple Migration Tasks in a later step. You can click on the “Test endpoint connection (optional)” tab to verify that the access configurations to access the PostgreSQL database are configured correctly.
AWS DMS versions 3.4.7 and later require that you configure AWS DMS to use VPC endpoints to all your source and target endpoints that interact with certain Amazon Web Services. Click here to configure VPC endpoints as AWS DMS source and target endpoints.
Step 3.3 Create a DMS Target Endpoint for every PostgreSQL database table
The DMS Target Endpoint specifies the name of the Kinesis Stream that is the target of a migration task. Create a DMS Target Endpoint as follows:
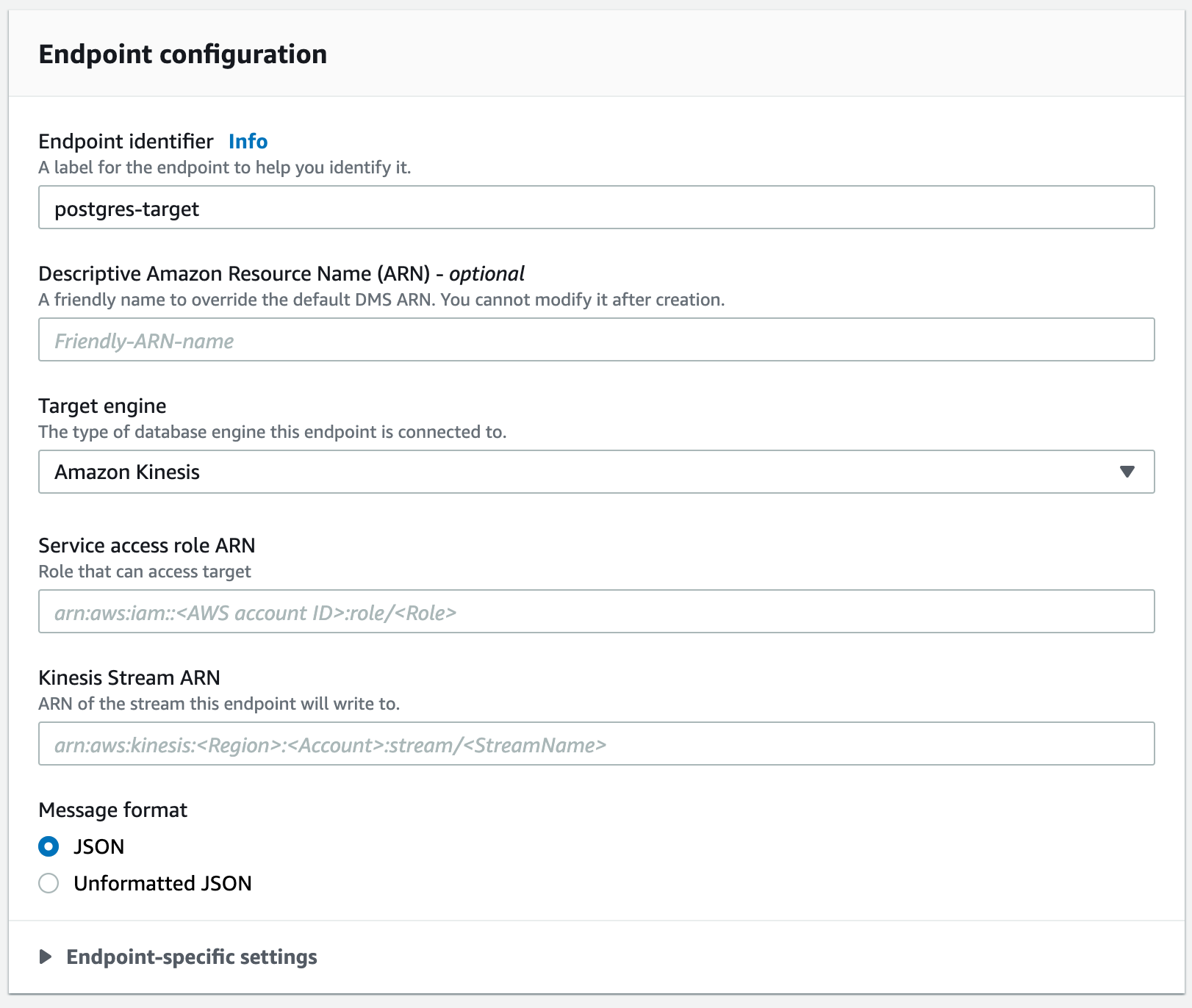
Pick Amazon Kinesis as the Target Engine. Enter the ARN of the Kinesis Stream created in Step 2.1 in the Kinesis Stream ARN field. Additionally, enter the Service access role ARN of the role created in Step 2.2.
Again, AWS DMS versions 3.4.7 and later require that you configure AWS DMS to use VPC endpoints to all your target endpoints. Follow these instructions to configure VPC endpoints.
You can click on the “Test endpoint connection (optional)” tab to verify that the access configurations to access the Kinesis Stream service are configured correctly.
Step 3.4 Create a DMS Database Migration Task to migrate a PostgreSQL table to a Kinesis Stream
A Migration Task connects one specific PostgreSQL database table on a specific PostgreSQL database to a specific Kinesis Stream. Use the AWS Console to specify the following:
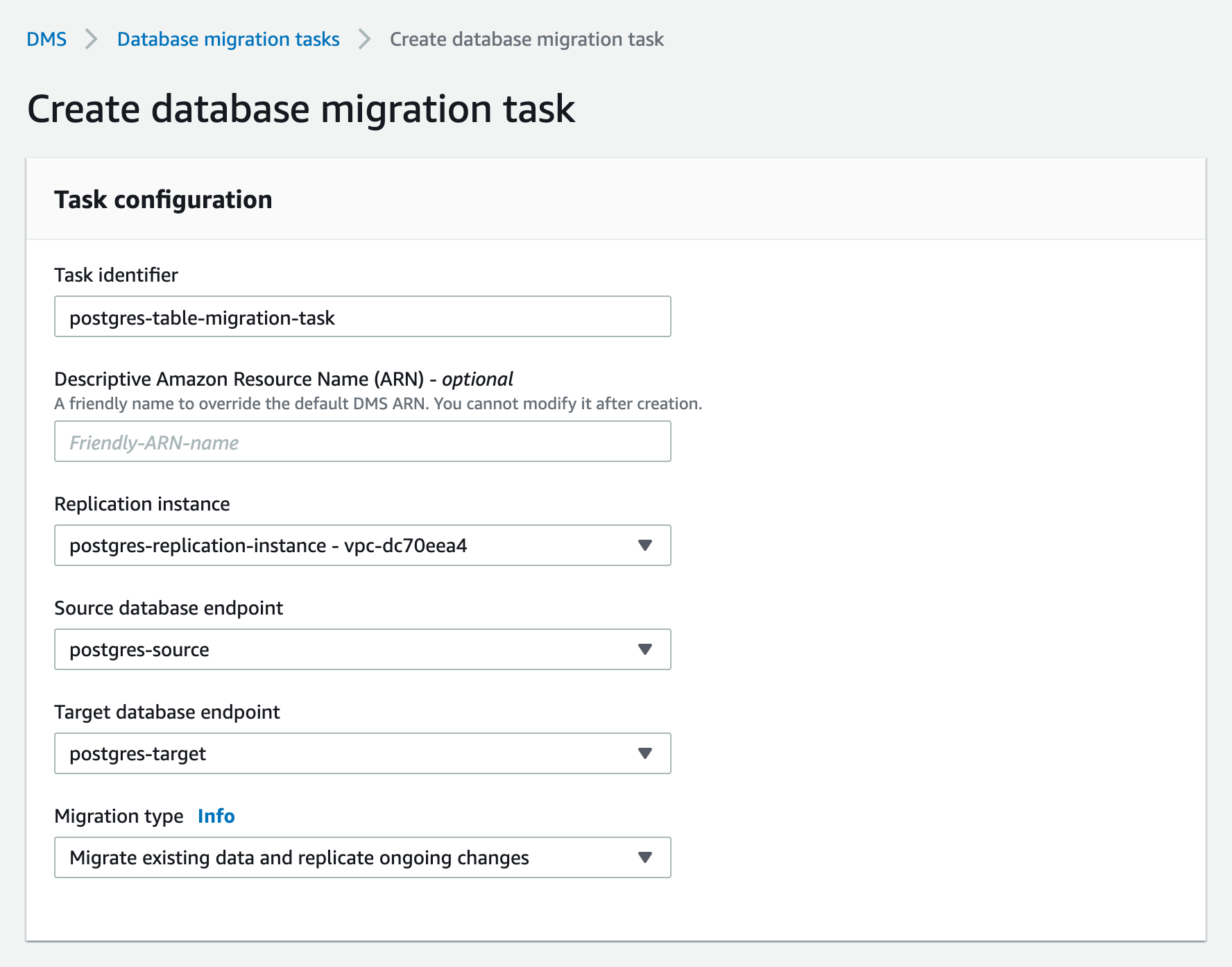
Pick the option for Migration type as “Migrate existing data and replicate ongoing changes”. This option does a full dump of the PostgreSQL database table to Kinesis first, followed by continuous replication through PostgreSQL CDC using the same Kinesis Stream. Specify the following task settings:
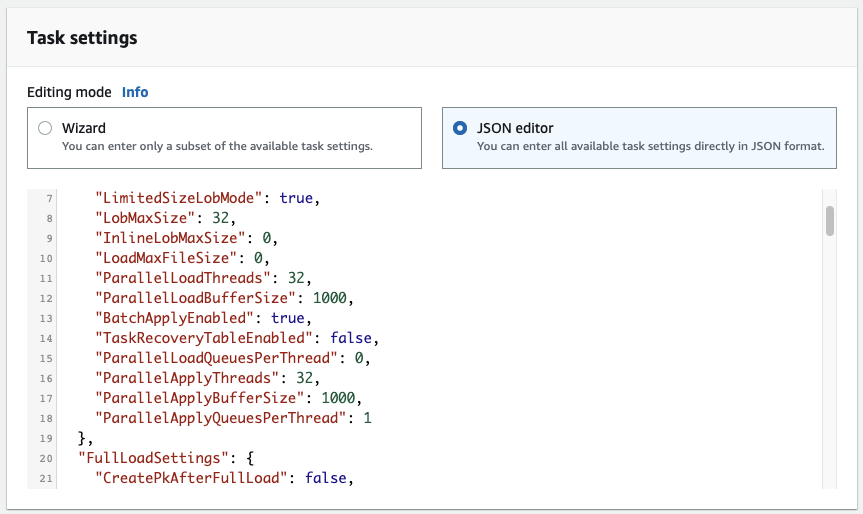
Configure these DMS configuration settings as required if you are working with a large table or if your update rate to your table is high.
"TargetMetadata": {
"ParallelLoadThreads": 32,
"ParallelLoadBufferSize": 1000,
"BatchApplyEnabled": true,
"ParallelApplyThreads": 32,
"ParallelApplyBufferSize": 1000,
"ParallelApplyQueuesPerThread": 128,
"ParallelLoadQueuesPerThread": 128,
}.
"FullLoadSettings": {
"CommitRate": 50000,
"MaxFullLoadSubTasks": 49,
},
The name of the PostgreSQL table that you want to migrate is specified in the section titled Table Mappings. Note that if you are migrating data from a partitioned table in PostgreSQL, you must specify the partition table name(s) in your selection rule rather than the parent table name. You must create a selection rule with the appropriate Table name field for each partition in the partitioned table.
Here is an exmaple where a table named customers in a database named rockset is being configured:
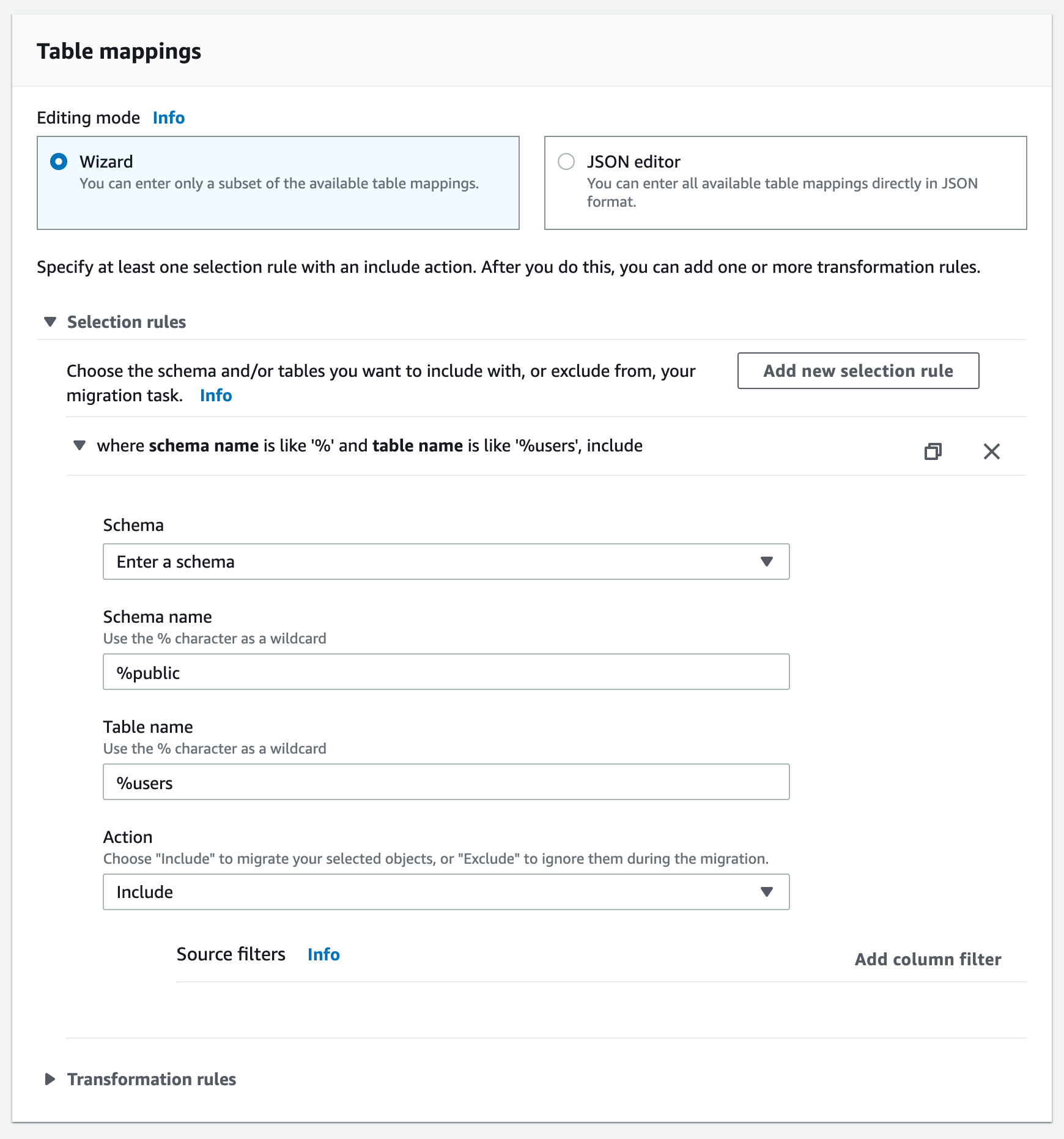
You can switch on Pre-migration assessment to verify that the settings are accurate. If you switch on the assessment then remember to manally start the task once the pre-migration assessment is complete.
Now that you have completed steps 1-3, you are ready to create the Rockset Kinesis integration.
Creating a Rockset Collection
- Navigate to the Collections page in the Rockset Console and select the "PostgreSQL" tile under Managed Integrations. This will
guide you through a series of steps to follow to set up the Kinesis Intergration needed to create the collection.
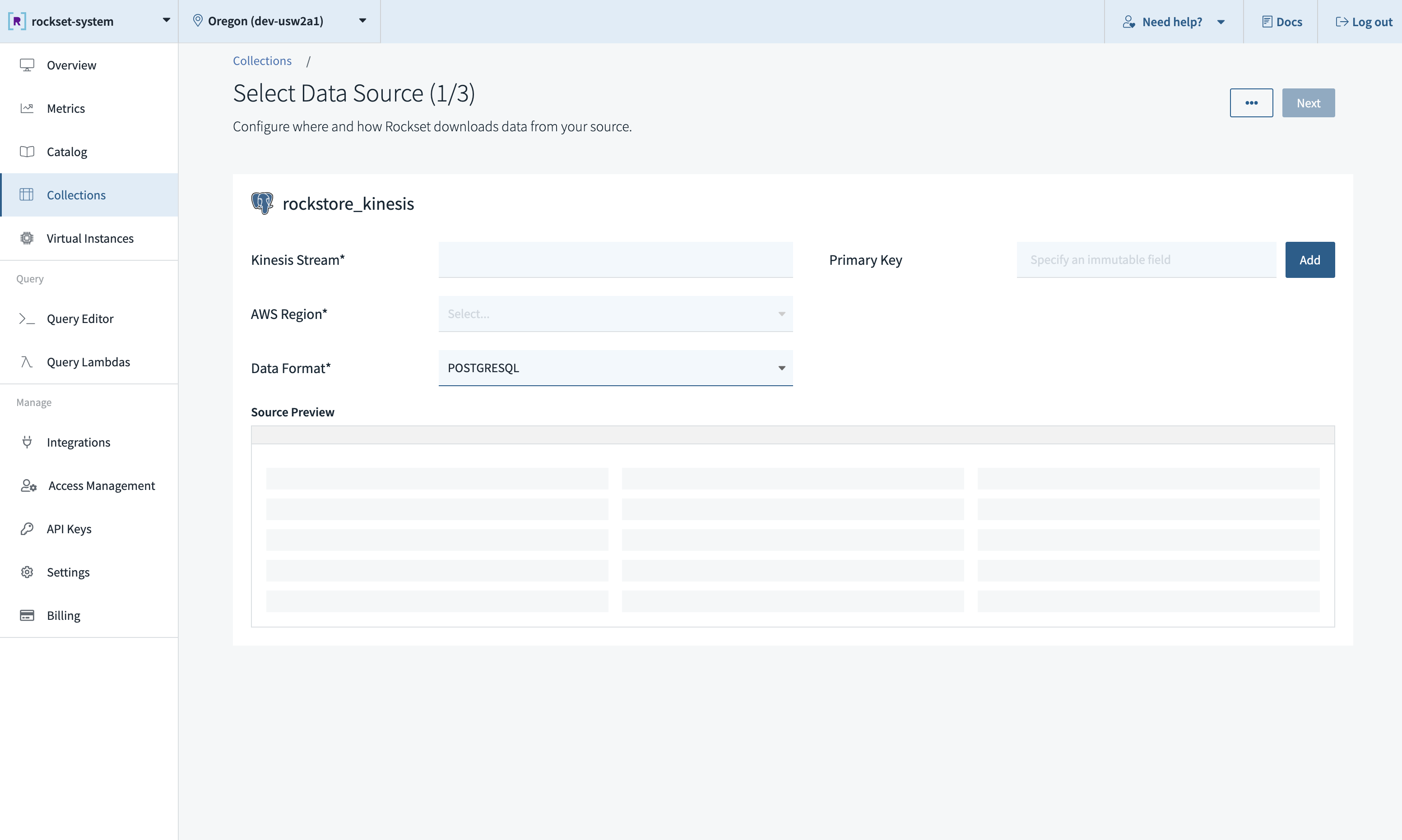
- Populate the fields as shown below. Note that Format must be set to
POSTGRESQL. Also, it is mandatory to specify an immutable primary key from the source PostgreSQL table during collection creation.
Ingesting Complex Types
The following is a table of custom SQL expressions that you can apply to fields as part of your collection's ingest transformation to ingest them with the desired type.
| PostgreSQL Data Type | Supported By DMS | Rockset Data Type | Rockset Ingest Transformation SQL Expression |
|---|---|---|---|
| INTEGER | Y | int | None |
| SMALLINT | Y | int | None |
| BIGINT | Y | int | None |
| NUMERIC/DECIMAL(p,s) | Y (where {'0<p<39 and 0<s)'} | float | None |
| NUMERIC/DECIMAL | Y (where p>38 or p=s=0) | float | None |
| REAL | Y | float | None |
| DOUBLE | Y | float | None |
| SMALLSERIAL | Y | int | None |
| SERIAL | Y | int | None |
| BIGSERIAL | Y | int | None |
| MONEY | Y | float | None |
| CHAR | Y | string | None |
| CHAR(n) | Y | string | None |
| VARCHAR | Y | string | None |
| VARCHAR(N) | Y | string | None |
| TEXT | Y | string | None |
| BYTEA | Y | bytes | FROM_HEX(SUBSTR(bytea_column, 3)) |
| TIMESTAMP | Y | timestamp | PARSE_TIMESTAMP('%Y-%m-%dT%H:%M:%SZ', timestamp_column) |
| TIMESTAMP(Z) | Y | timestamp | PARSE_TIMESTAMP('%Y-%m-%dT%H:%M:%SZ', timestamp_column) |
| DATE | Y | date | PARSE_DATE('%Y-%m-%d', date_column) |
| TIME | Y | time | PARSE_TIME('%H:%M:%S', time_column) |
| TIME (z) | Y | time | PARSE_TIME('%H:%M:%S', time_column) |
| INTERVAL | Y | microsecond_interval | PARSE_DURATION_SECONDS(interval_column) |
| INTERVAL | Y | month_interval | PARSE_DURATION_MONTHS(interval_column) |
| BOOLEAN | Y | bool | CAST(boolean_column as bool) |
| ENUM | N | NA | NA |
| CIDR | N | NA | NA |
| INET | N | NA | NA |
| MACADDR | N | NA | NA |
| TSVECTOR | N | NA | NA |
| TSQUERY | N | NA | NA |
| XML | Y | string | None |
| POINT | N | NA | NA |
| LINE | N | NA | NA |
| LSEG | N | NA | NA |
| BOX | N | NA | NA |
| PATH | N | NA | NA |
| POLYGON | N | NA | NA |
| CIRCLE | N | NA | NA |
| JSON | Y | object | JSON_PARSE(json_column) |
| ARRAY | Y | array | PG_ARRAY_PARSE(array_column, 'elemtype[]') |
| COMPOSITE | N | NA | NA |
| RANGE | N | NA | NA |
| LINESTRING | N | NA | NA |
| MULTIPOINT | N | NA | NA |
| POLYGON | N | NA | NA |
| MULTILINESTRING | N | NA | NA |
| MULTIPOLYGON | N | NA | NA |
| GEOMETRYCOLLECTION | N | NA | NA |
Unsupported Operations
DDL operations such as CREATE DDL, ALTER DDL, and DROP DDL are currently unsupported. Table level operations such as TRUNCATE and ALTER TABLE are also currently unsupported.
Best Practices
We recommend only using one Kinesis stream per collection, i.e. one stream per PostgreSQL table. If multiple collections read from the same Kinesis stream, they will encounter rate limits imposed by Kinesis, which results in throttling. When encountering throttling, Rockset retries with backoff, which can increase data ingestion latencies. Read more about the limits here.
If using one stream for multiple tables, please note the following:
- Any table exported to the stream must have the
idfield even if the tables are not included in any Rockset collection. - The Primary Key when creating a Rockset collection using the Kinesis stream must be the
idfield.
Updated about 1 year ago