
Compute Architecture
Compute-Compute Separation
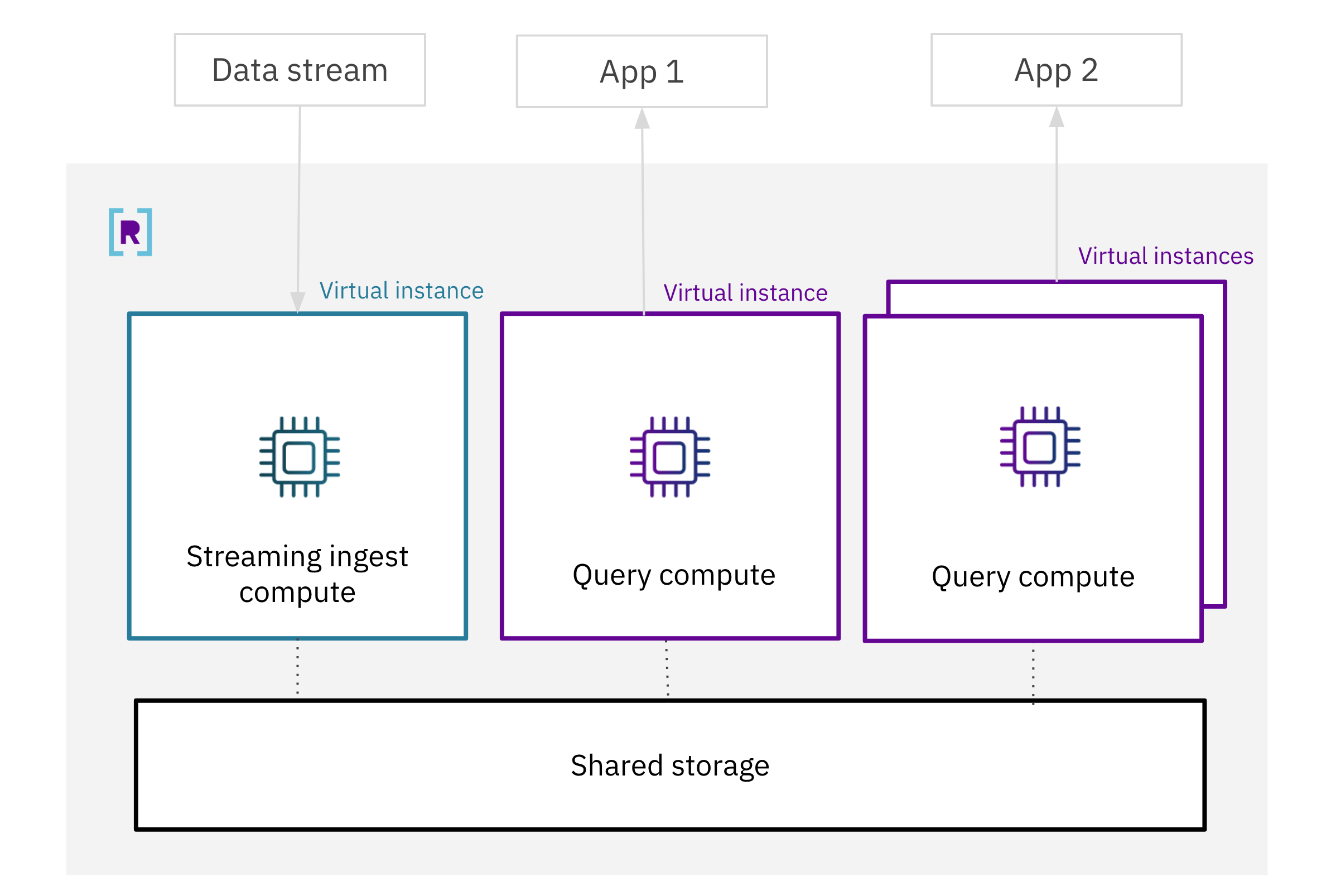
Compute-compute separation is an architecture that isolates the compute used for ingestion from the compute used for queries, allowing you to scale them independently. Multiple Virtual Instances can access the same, real-time datasets, and Virtual Instances can be quickly spun up or down to accommodate variable workloads.
This means you can efficiently scale Rockset by changing the sizes of your virtual instances or by spinning up new ones, while guaranteeing data freshness across all virtual instances.
Motivation
Compute-compute separation fundamentally addresses the issue of compute contention in a real-time database system. Running data ingestion and queries on the same compute unit can preserve the real-time nature of the data since reads can easily reflect recent writes. However, this comes with the caveat that a spike in writes will result in degraded query performance and vice-versa. In addition, queries from different applications are not isolated from each other and, thus, can negatively impact one another. Effectively, in a non compute-compute separated architecture, the read and write workloads for the data system must contend for the same set of compute resources.
Rockset’s compute-compute separated architecture completely isolates the compute resources used for data ingestion from the ones used for serving queries. A given virtual instance can be dedicated to data ingestion, dedicated to queries, or responsible for both workloads. Multiple virtual instances can be used to isolate workloads from different applications.
Architecture
Rockset’s architecture is designed to maintain the real-time nature of data even when ingestion and queries are not running on the same compute unit. It maintains this data freshness and consistency across multiple virtual instances, by setting one virtual instance (the Ingest VI) to perform the CPU intensive work associated with ingestion, and all other virtual instances (Query VIs) keep their in-memory state up-to-date by tailing updates from the Ingest VI. No on-disk state needs to be replicated because it is available to all virtual instances through the shared hot storage layer.
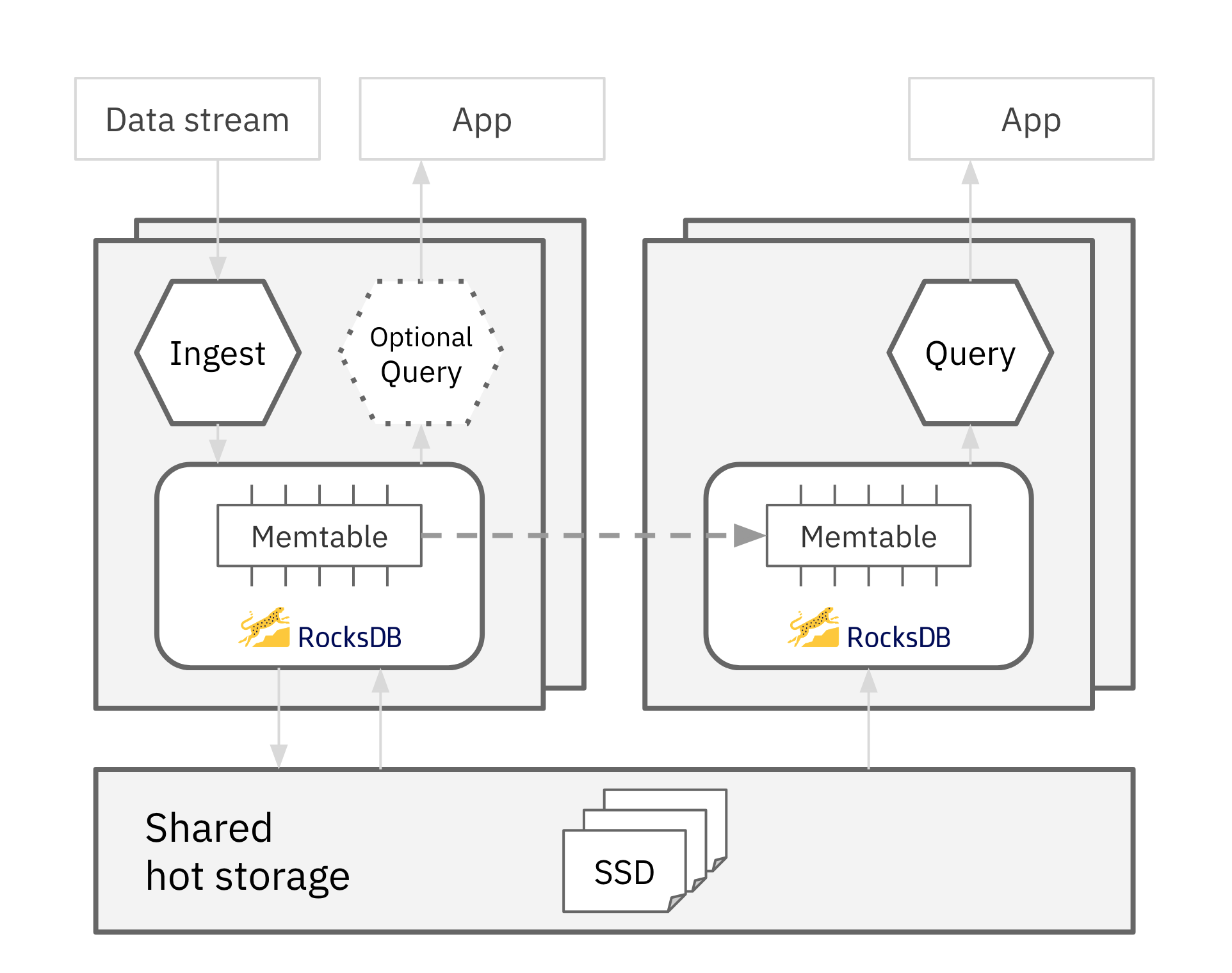 The CPU intensive work associated with ingestion includes:
The CPU intensive work associated with ingestion includes:
- Parsing input documents
- Performing Ingest Transformations
- Handling updates to existing documents
- Indexing
- Compaction
The design for compute-compute separation ensures only the Ingest VI handles the CPU intensive work associated with ingestion.
A shared hot storage tier enables compute-storage separation in the system, which is a pre-requirement for compute-compute separation. Compute-storage separation means that no data movement is required to spin up a new virtual instance, making the operation fast and lightweight.
By integrating both compute-storage separation and compute-compute separation, Rockset allows you to take full advantage of the elasticity of the cloud for your real-time analytics workloads.
FAQs
How do I decide if I should increase the size of my virtual instance or add an additional virtual instance?
Additional virtual instances can be used to isolate ingestion from queries and/or isolate workloads from different applications. To achieve the latency and throughput requirements for ingestion, queries, and/or a specific workload, you can increase the size of your virtual instance.
What is the data replication lag between the Ingest VI and the Query VIs?
To effectively power real-time data analytics, the data replication lag between the streaming ingest virtual instance and the query virtual instances is very low (on the order of tens of milliseconds).
How does a compute-compute separated architecture provide availability?
Isolating workloads on separate compute resources prevents noisy neighbor issues, thus improving reliability. Within a single virtual instance, Rockset maintains availability in the face of partial failures.
Want to learn more?
Check out our blog on Introducing Compute-Compute Separation, watch our technical deep dive How Rockset Isolates Streaming Ingest and Queries Using RocksDB, or read our blog on How Rockset Separates Compute and Storage Using RocksDB.
Updated over 1 year ago