
What is Rockset?
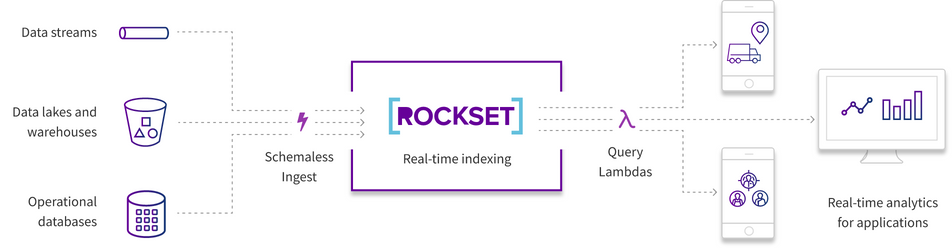
Rockset is a search analytics database which enables queries on massive, semi-structured data without operational burden. Rockset is serverless and fully managed. It offloads the work of managing configuration, cluster provisioning, denormalization, and shard / index management. Rockset is also SOC 2 Type II compliant and offers encryption at rest and in flight, securing and protecting any sensitive data. Most teams can ingest data into Rockset and start executing queries in less than 15 minutes.
With Rockset, ingested data is queryable within one second and analytical queries against that data typically execute in milliseconds. Rockset supports schemaless ingest for structured, semi-structured, geo, time-series, and embeddings data. Via Rockset’s Converged Index™, all data is automatically indexed three ways - column, row, and search - at the time of ingestion. The SQL query optimizer examines each query and chooses an execution plan for optimal performance. You will typically see query executions in the 100s of milliseconds on fresh data. Rockset is compute optimized, making it suitable for serving high concurrency applications in the sub-100TB range (or larger than 100s of TBs with rollups).
Why Rockset?
Rockset provides the following key features and benefits:
- Built-in Connectors
- Smart Schemas
- Full SQL Support
- Real-Time Aggregations
- Vector Search
- Query Lambdas
- Developer Tools
Built-in Connectors
Rockset has pre-built integrations for:
- Amazon DynamoDB
- Amazon Eventbridge
- Amazon Kinesis
- Amazon MSK
- Amazon S3
- Apache Kafka
- Azure Blob Storage
- Azure Event Hubs
- Azure Service Bus
- Confluent Cloud
- Druid
- Elasticsearch
- Google Cloud Storage
- Microsoft SQL Server
- MongoDB
- MongoDB Atlas
- MongoDB Kafka
- MongoDB Self Managed
- MSSQL
- MySQL
- Oracle
- PostgreSQL
- Snowflake
As you follow our step-by-step tutorials, Rockset will automatically load your data within seconds so you can begin making SQL queries immediately. New data can be queried with a p95 (95th percentile latency) of two seconds. Rockset can initially load the data in bulk and then continuously ingest upwards of millions of events per second, to stay in sync with your data source. No ETL tools are required for this process.
Rockset can also follow CDC streams from both RDBMS and NoSQL data stores.
If your data is not in any of these sources or you want to stream events directly into Rockset, you can always use the Write API to directly write data to your Rockset collections. To request support for a new data source, reach out to our support team at support@rockset.com.
Smart Schemas
Rockset ingests your data without the need for pre-built schemas. Smart schemas are automatically generated based on the exact fields and types present in the ingested data. The smart schema represents and enables SQL queries for semi-structured data, nested objects and arrays, mixed types and nulls. You can also define your own Ingest Transformations to be applied as documents are ingested into Rockset to create new fields, manipulate existing ones, or configure rollups from your data source.
Learn more about how smart schemas are generated in Rockset.
Full SQL Support
Rockset supports full SQL including:
And queries over all types of fields (including heavily nested objects and arrays) and on any semi-structured data. This enables the use and flexibility of SQL queries over data in supported data sources, even if they don't natively support SQL.
See our SQL Reference for the full list of all functions available for writing SQL queries in Rockset.
Real-Time Aggregations
Real-time aggregations, or Rollups, are a class of Ingest Transformations that enable you to aggregate data as it is ingested, combining multiple documents into one.
As new data comes in, Rockset will transform and aggregate it before storing it in your rollup collection. For time-series data, even out-of-order data arrivals that come in after the fact will be properly aggregated automatically.
Vector Search
Rockset supports vector search to help you run your real-time ML and analytics applications. Seamlessly mix similarity searches over your embeddings with complex joins, selective predicates, and everything else you expect from SQL on Rockset.
Explore more about vector search and how to leverage it for your use case in Rockset.
Query Lambdas
Query Lambdas are named, parameterized SQL queries stored in Rockset that can be executed from a dedicated REST endpoint. With Query Lambdas, you can save and enforce version control for your SQL queries and integrate them into your CI/CD workflows.
Query Lambdas are fully supported in all of Rockset’s official client libraries and the Rockset API. Use the Rockset CLI to create, manage, and deploy your Query Lambdas directly from your local computer.
Watch our tutorial on how to build applications using Query Lambdas.
Developer Tools
Rockset has several tools, adapters, and libraries which wrap the Rockset REST API. These can be used to deploy Rockset resources and programmatically insert, update, and query data from your application's code. The following libraries and tools can be used to assist with data management:
If you want to use Rockset and compose SQL queries inside your IDE, check out our VS Code Extension.
How does it work?
The following subsections describe key aspects on how Rockset works:
- Converged Index™
- Scale Compute and Storage Independently
- Compute-Compute Separation
- Serverless Auto-Scaling in the Cloud
- Enterprise-Grade Security
Converged Index™
All fields, including deeply nested fields, are automatically indexed in a Converged Index™ as each record is ingested. They include three indexes:
- Inverted index
- Columnar index
- Row index
A Converged Index™ allows analytical queries on large datasets to return in milliseconds. Using Rockset, you will never have to manually define, create, or update your indexes. Rockset automatically manages this for you. You can customize Rockset for efficient, cost-optimized, and massive-scale applications.
Read more about how Rockset builds a Converged Index™ and other design concepts in Rockset’s Architecture Whitepaper.
Scale Compute and Storage Independently
Using Rockset, you can scale compute and storage resources independently for the best balance of price and performance. As your data size grows, you can choose the right amount of compute for the query performance you need at any given time. Hot storage and ingest costs are charged at a fixed rate, while compute resources are based on your Virtual Instance Type.
See Rockset’s full pricing model.
Compute-Compute Separation
Compute-compute separation is an architecture that isolates the compute used for ingestion from the compute used for queries, allowing you to scale them independently. Multiple virtual instances can access the same, real-time datasets, and virtual instances can be quickly spun up or down to accommodate variable workloads. This means you can efficiently scale Rockset by changing the sizes of your virtual instances or by spinning up new ones, while guaranteeing data freshness across all virtual instances.
Learn more about our compute architecture here.
Serverless Auto-Scaling in the Cloud
Rockset uses a modern, cloud-native architecture that auto-scales in the cloud, and automates cluster provisioning and index management. This significantly minimizes any operational overhead because you will never need to provision capacity or manage servers.
For more information about Rockset's architecture and its performance benchmarks, see the Evaluating Data Latency for Real-Time Databases white paper.
Enterprise-Grade Security
Stored data is encrypted using AES-256, and SSL is used in transit. In addition, you can mask sensitive information using an Ingest Transformation. Read more about our security features including SAML, OAuth, and Okta for single sign-on in the Security section of our documentation. See our Data Privacy Addendum for additional information.
Next steps
To get started, create a Rockset account. See our Quickstart for a 10-minute tutorial on how to get started running queries on Rockset with sample data. Or, start by load data from your own data sources. If you have any questions, please contact us at support@rockset.com. We're always happy to help!
Updated 9 months ago