
CDC
This document covers how to bring change data capture (CDC) data from your source into Rockset. CDC data is any stream of records that represent insert/update/delete operations taking place on some source system.
If you're looking for the automated CDC templates, skip ahead to their reference below.
Optimized for CDC
Rockset's ingestion platform includes all the building blocks required to ingest CDC data in real-time.
- Our managed Data Source Integrations are purpose built for real-time ingestion and include several source types which are popular conduits for CDC data. Our Write API also enables real-time, push-based sources.
- Ingest Transformations give you the power to drop, rename or combine fields, filter out incoming rows, cast, or otherwise transform the incoming CDC stream in real-time without the need for additional data pipelines.
- Rockset's indexes are fully mutable, meaning updates and deletes can be efficiently applied in real-time so you save on compute even while queries run on the freshest data.
How To Ingest CDC Data
Ingesting CDC data is largely automated with CDC templates discussed below, but here we'll explain how it works in case your desired CDC format does not have a corresponding template, or you want to configure it manually.
Once you bring your CDC data into one of Rockset's supported data sources, or configure your application to send CDC records to our Write API, you need to create a Collection in the Rockset console and configure an ingest transformation to
- Map the CDC fields to Rockset's special fields
_op,_id, and_event_time. - Project the source fields you want indexed in Rockset.
- (Optionally) Filter out any CDC records you want to ignore.
Mapping Special Fields
You can read more about the semantics of Rockset's special fields here.
_op
The _op field is how Rockset knows how to handle incoming records from your source. Based on the value of _op in a record, that record can lead to an insert, update, delete, replace, or some combination of those operations on your collection.
The supported operation types (case insensitive) are: INSERT, UPDATE, UPSERT (default), DELETE, REPLACE, and REPSERT. For more on their exact semantics, refer to the documentation for _op.
CDC formats typically have their own unique codes for whether the record is an insert, update, delete, etc. You can write your transformation to account for this using conditional expressions like CASE or IF.
For example, if a format has a field changeType which is one of [CREATE, UPDATE, DELETE], then you would map this to _op with an expression like
SELECT IF(changeType = 'DELETE', 'DELETE', 'UPSERT') AS _op
or if the format is such that for delete operations an after field is null, otherwise it is not null, then
SELECT CASE WHEN after IS NULL THEN 'DELETE' ELSE 'UPSERT' END AS _op
Tip: A common gotcha here is remembering that SQL uses single quotes for string literals. So
having a predicate comparing to "DELETE" (double quotes) will actually look for a field called
DELETEand not do what you're intending.
_id
The primary key of your source needs to map to the _id of your documents in Rockset so that updates and deletes are properly applied. In the case of single primary key, this is as simple as
SELECT sourceFieldName AS _id
or in the case where your primary key is not a string type in your source system (since _id must always be a string)
SELECT CAST(sourceFieldName AS string) AS _id
In case of compound primary keys in your source, you need to map the fields of the primary key to a unique string. We have a built-in SQL function, ID_HASH, exactly for this purpose.
SELECT ID_HASH(sourceField1, sourceField2) AS _id
We strongly advise you use the ID_HASH function for these kinds of cases. But if you do choose to use another hash function, note that most have a return type of bytes, whereas _id must be a string type. Therefore if you use some other hash to construct _id, you should wrap it in another function like TO_BASE64 or TO_HEX that takes a bytes argument and returns a string result.
Note on Rollup Collections
Rollup collections are insert only and do not allow a custom mapping for _id. For that reason you cannot do the above mapping for rollup collections and any update/delete deltas coming from your source will be rejected.
_event_time
Though not strictly necessary like the special fields above, it is good practice to create a custom mapping for the document timestamp _event_time if the CDC format exposes the time of record creation. _event_time must be either a timestamp or an integer that represents the microseconds since epoch.
You can use any of the relevant timestamp functions to do this conversion, e.g.
-- timestamps formated like `2022-10-26T18:19:06.705792Z`
SELECT PARSE_TIMESTAMP_ISO8601(timestampField) AS _event_time
-- unix timestamp (seconds since epoch)
SELECT TIMESTAMP_SECONDS(unixTsField) AS _event_time
Since _event_time is an immutable field on a document, you only need to set it for insert type CDC records, not update or delete. This means you can combine this with the _op logic like
SELECT IF(changeType = 'INSERT', PARSE_TIMESTAMP_ISO8601(timestampField), undefined) AS _event_time
Else Case Warning
Importantly, the else case above uses
undefinedwhich is equivalent to "does not exist". You cannot set it toNULLbecause a null event time is invalid and will cause the ingestion of that document to error.
Projecting Source Fields
Typically CDC records have a deeply nested structure and it's a good idea to pull out the fields you want to persist and index in your Rockset collection explicitly.
For example consider a CDC record of the form
{
"changeType": "INSERT",
"metadata": { "timestamp": "2022-10-16T00:00:00Z" },
"payload": { "field1": "value1", "field2": "value2" }
}
Presumably here you want field1 and field2 to be ingested, so you should explicitly project them like (ommitting special fields for brevity)
SELECT _input.payload.field1, _input.payload.field2
FROM _input
You can also take this opportunity to do any field pruning or renaming, e.g.
-- rename field1 and drop field2
SELECT _input.payload.field1 AS user_id
FROM _input
Filtering Records
The WHERE clause of the ingest transformation can be used to filter out CDC records that are unneeded. This can be useful if you have CDC control records in the stream (e.g. dropping a table) that you don't want ingested alongside data records. It can also be valuable if you have multiple CDC streams being piped through the same source and you want to only ingest some of them.
For example
SELECT ...
FROM _input
WHERE recordType = 'data' AND _input.metadata.table_name = 'users'
Considerations
A few considerations to keep in mind when ingesting CDC data to ensure the smoothest experience
- Only event stream sources provide ordering guarantees during ingestion. This means that for CDC records that include updates and deletes, bringing that data from another source type such as an object store may lead to out of order processing and unexpected behavior.
- Rollup collections are insert only, so updates/deletes are not supported. Though, you can delete the whole roll up document in the collection using the delete document API endpoint.
- Rockset does not support updating the primary key (_id) of a document. If you update primary keys
in your source, you'll have to delete the original document in Rockset then create a new one. Some CDC formats offer options to represent primary key updates in this way.
CDC Transformation Templates
To help automate the process of bringing CDC data into Rockset, we have built support for a number of popular CDC formats directly into the ingest transformation process of creating a collection. These transformation templates can automatically infer which CDC format you have, and construct some or all of the transformation for you out of the box.
Below is a reference of the CDC formats for which automated templates are supported.
CDC Tips
Based on the specific configuration of your upstream CDC engine, it is possible the formats differ slightly from the expected format these templates reference. In that case, you can use the template as a starting point to automate many aspects but may need to manually adjust some of the sections where your data model differs from what is expected.
In order to get the most out of these templates, your source should have some records available for previewing during the collection creation process. This means it is preferable to first configure your upstream CDC system to send records to a source and then to go through the collection creation process in the Rockset console. For cases where that is not possible, for example when sending records to the write api, consider first downloading a few sample CDC records to a file and creating a sample file upload collection to iterate on the transformation before creating your final collection.
Debezium
For Debezium data, both JSON encoded and Avro encoded CDC records are supported.
Refer to the Debezium docs for any source-specific limitations, including how data types are mapped.
JSON
This is for Debezium records encoded using a JSON serializer to a destination like Kafka.
Expected Structure:
payload.opis one of[r, c, u, d].dis mapped to_op=DELETEand the rest to_op=UPSERT.- For delete operations,
payload.beforecontains the full document, for other operations it is in
payload.after. payload.source.ts_msis an integer representing milliseconds since epoch.
Example Record:
{
"payload": {
"before": null,
"after": {
"shipment_id": 1,
"order_id": 2,
"date_created": "2021-01-21",
"status": "READY"
},
"source": {
"version": "1.4.2.Final",
"connector": "postgresql",
"name": "postgres",
"ts_ms": 1665014112483,
"snapshot": "false",
"db": "shipment_db",
"schema": "public",
"table": "shipments",
"txId": 495,
"lsn": 23875776,
"xmin": null
},
"op": "c",
"ts_ms": 1665014112535,
"transaction": null
}
}
The resulting transformation that is automatically generated based on the sample record and specifying the primary key being order_id is
SELECT
IF(_input.payload.op = 'd', 'DELETE', 'UPSERT') AS _op,
IF(_input.payload.op = 'd',
CAST(_input.payload.before.order_id AS string),
CAST(_input.payload.after.order_id AS string)
) AS _id,
IF(_input.payload.op IN ('r', 'c'), TIMESTAMP_MILLIS(_input.payload.ts_ms), undefined) AS _event_time,
_input.payload.after.date_created,
_input.payload.after.order_id,
_input.payload.after.shipment_id,
_input.payload.after.status
FROM _input
WHERE _input.payload.op IN ('r', 'c', 'u', 'd')
Limitations:
- Primary key updates are not supported
Avro
This is for Debezium records encoded using an AVRO serializer to a destination like Kafka.
Expected Structure:
opis one of[r, c, u, d].dis mapped to_op=DELETEand the rest to_op=UPSERT.- For delete operations,
before.Valuecontains the full document, for other operations it is in
after.Value. source.ts_msis an integer representing milliseconds since epoch.
Example Record:
{
"before": null,
"after": {
"Value": {
"shipment_id": 30500,
"order_id": 10500,
"date_created": {
"string": "2021-01-21"
},
"status": {
"string": "COMPLETED"
}
}
},
"source": {
"version": "1.4.2.Final",
"connector": "postgresql",
"name": "postgres",
"ts_ms": 1665011053089,
"snapshot": {
"string": "true"
},
"db": "shipment_db",
"schema": "public",
"table": "shipments",
"txId": {
"long": 491
},
"lsn": {
"long": 23873424
},
"xmin": null
},
"op": "r",
"ts_ms": {
"long": 1665011053092
},
"transaction": null
}
The resulting transformation that is automatically generated based on the sample record and specifying the primary key being order_id is
SELECT
IF(_input.op = 'd', 'DELETE', 'UPSERT') AS _op,
IF(_input.op = 'd',
CAST(_input.before.Value.order_id AS string),
CAST(_input.after.Value.order_id AS string)
) AS _id,
IF(_input.op IN ('r', 'c'), TIMESTAMP_MILLIS(_input.source.ts_ms), undefined) AS _event_time,
_input.after.Value.date_created.string AS date_created,
_input.after.Value.order_id,
_input.after.Value.shipment_id,
_input.after.Value.status.string AS status
FROM _input
WHERE _input.op IN ('r', 'c', 'u', 'd')
Limitations:
- Primary key updates are not supported
- Avro nests certain fields, e.g. above having
{"date_created: {"string": "2021-01-21}}. We try to
unpack these in the transformation automatically, but you may need to do additional path extraction and/or casting on the extracted value.
AWS Data Migration Service (DMS)
Refer to the DMS docs for any source-specific limitations, including how data types are mapped.
Expected Structure:
metadata.record-typeis one of[control, data]. Control records are filtered out in the WHERE
clause.- For data records,
metadata.operationis one of[load, insert, update, delete].deleteis
mapped to_op=DELETE, and the rest to_op=UPSERT. metadata.timestampis an ISO 8601 formatted timestamp string.- The full document is in
data.
Example Record:
{
"data": {
"order_id": 1,
"shipment_id": 2,
"status": "CREATED"
},
"metadata": {
"transaction-id": 86925843104323,
"partition-key-type": "schema-table",
"record-type": "data",
"table-name": "shipments",
"operation": "insert",
"timestamp": "2021-03-22T21:36:48.479850Z",
"schema-name": "rockset"
}
}
The resulting transformation that is automatically generated based on the sample record and specifying the primary key being order_id is
SELECT
IF(_input.metadata.operation = 'delete', 'DELETE', 'UPSERT') AS _op,
CAST(_input.data.order_id AS string) AS _id,
IF(_input.metadata.operation IN ('load', 'insert'),
PARSE_TIMESTAMP_ISO8601(_input.metadata.timestamp),
undefined
) AS _event_time,
_input.data.order_id,
_input.data.shipment_id,
_input.data.status
FROM _input
WHERE _input.metadata."record-type" = 'data'
Limitations:
- Since control records are ignored, operations like adding/removing columns, or even dropping the source table are unreflected in Rockset.
Google Cloud Datastream
Refer to the Datastream docs for any source-specific limitations, including how data types are mapped.
Expected Structure:
source_metadata.change_typeis one of[INSERT, UPDATE, UPDATE-DELETE, UPDATE-INSERT, DELETE].
UPDATE_DELETEandDELETEare mapped to_op=DELETE, and the rest to_op=UPSERT.source_metadata.source_timestampis an ISO 8601 formatted timestamp string.- The full document is in
payload.
Example Record:
{
"stream_name": "projects/myProj/locations/myLoc/streams/Oracle-to-Source",
"read_method": "oracle-cdc-logminer",
"object": "SAMPLE.TBL",
"uuid": "d7989206-380f-0e81-8056-240501101100",
"read_timestamp": "2019-11-07T07:37:16.808Z",
"source_timestamp": "2019-11-07T02:15:39Z",
"source_metadata": {
"log_file": "",
"scn": 15869116216871,
"row_id": "AAAPwRAALAAMzMBABD",
"is_deleted": false,
"database": "DB1",
"schema": "ROOT",
"table": "SAMPLE",
"change_type": "INSERT",
"tx_id": "",
"rs_id": "0x0073c9.000a4e4c.01d0",
"ssn": 67
},
"payload": {
"THIS_IS_MY_PK": "1231535353",
"FIELD1": "foo",
"FIELD2": "TLV"
}
}
The resulting transformation that is automatically generated based on the sample record and specifying the primary key being THIS_IS_MY_PK is
SELECT
IF(_input.source_metadata.change_type IN ('DELETE', 'UPDATE-DELETE'), 'DELETE', 'UPSERT') AS _op,
CAST(_input.payload.THIS_IS_MY_PK AS string) AS _id,
PARSE_TIMESTAMP_ISO8601(_input.source_timestamp) AS _event_time,
_input.payload.FIELD1,
_input.payload.FIELD2,
_input.payload.THIS_IS_MY_PK
FROM _input
Striim
Refer to the Striim docs for any source-specific limitations, including how data types are mapped. The Striim template is compatible with the JSON and Avro formatters.
Expected Structure:
metadata.OperationNameis one of[INSERT, UPDATE, DELETE].DELETEis mapped to_op=DELETE,
and the rest to_op=UPSERT.metadata.CommitTimestampis a timestamp string corresponding to the format specification
%d-%b-%Y %H:%M:%S.datacontains the full document for all records;beforecontains the prior version of the
document in the case of updates.
Example Record:
{
"data": {
"ID": "1",
"NAME": "User One"
},
"before": null,
"metadata": {
"TABLENAME": "Employee",
"CommitTimestamp": "12-Dec-2016 19:13:01",
"OperationName": "INSERT"
}
}
The resulting transformation that is automatically generated based on the sample record and specifying the primary key being ID is
SELECT
IF(_input.metadata.OperationName = 'DELETE', 'DELETE', 'UPSERT') AS _op,
CAST(_input.data.ID AS string) AS _id,
IF(_input.metadata.OperationName = 'INSERT', PARSE_TIMESTAMP('%d-%b-%Y %H:%M:%S', _input.metadata.CommitTimestamp), undefined) AS _event_time,
_input.data.ID,
_input.data.NAME
FROM _input
WHERE _input.metadata.OperationName IN ('INSERT', 'UPDATE', 'DELETE')
Limitations:
- Striim must be configured in either Async mode or Sync mode with batching disabled because you
cannot extract multiple Rockset documents from a single incoming record.
Arcion
Refer to the Arcion docs for any source-specific limitations, including how data types are mapped.
Expected Structure:
opTypeis one of[I, U, D].Dis mapped to_op=DELETE, and the rest to_op=UPSERT.cursoris a serialized JSON object whosetimestampfield is a number representing
millieseconds since epoch.- For insert and update records, the full document is in
after; for delete records, the full
document is inbefore.
Example Record:
{
"tableName": {
"namespace": {
"catalog": "tpch_scale_0_01",
"schema": "default_schema",
"hash": -27122659
},
"name": "nation",
"hash": -1893420405
},
"opType": "I",
"cursor": "{\"extractorId\":0,\"timestamp\":1657516978000,\"extractionTimestamp\":1657516979166,\"log\":\"log-bin.000010\",\"position\":11223,\"logSeqNum\":1,\"slaveServerId\":1,\"v\":2}",
"before": {
"n_comment": "null",
"n_nationkey": "null",
"n_regionkey": "null",
"n_name": "null"
},
"after": {
"n_comment": "Testing comment",
"n_nationkey": "101",
"n_regionkey": "2",
"n_name": "Testing name1"
},
"exists": {
"n_comment": "1",
"n_nationkey": "1",
"n_regionkey": "1",
"n_name": "1"
},
"operationcount": "{\"insertCount\":31,\"updateCount\":1,\"deleteCount\":1,\"replaceCount\":0}"
}
The resulting transformation that is automatically generated based on the sample record and specifying the primary key being n_nationkey is
SELECT
IF(opType = 'D', 'DELETE', 'UPSERT') AS _op,
IF(opType = 'D',
CAST(_input.before.n_nationkey AS string),
CAST(_input.after.n_nationkey AS string)
) AS _id,
IF(opType = 'I', TIMESTAMP_MILLIS(JSON_PARSE(cursor).timestamp), undefined) AS _event_time,
_input.after.n_comment,
_input.after.n_name,
_input.after.n_nationkey,
_input.after.n_regionkey
FROM _input
Example Walkthrough
This walkthrough shows the process of creating a collection on top of some sample CDC data. Here we'll work with Debezium CDC coming from a Postgres instance and being sent to a Kafka topic using a JSON serializer, which we assume has already been configured.
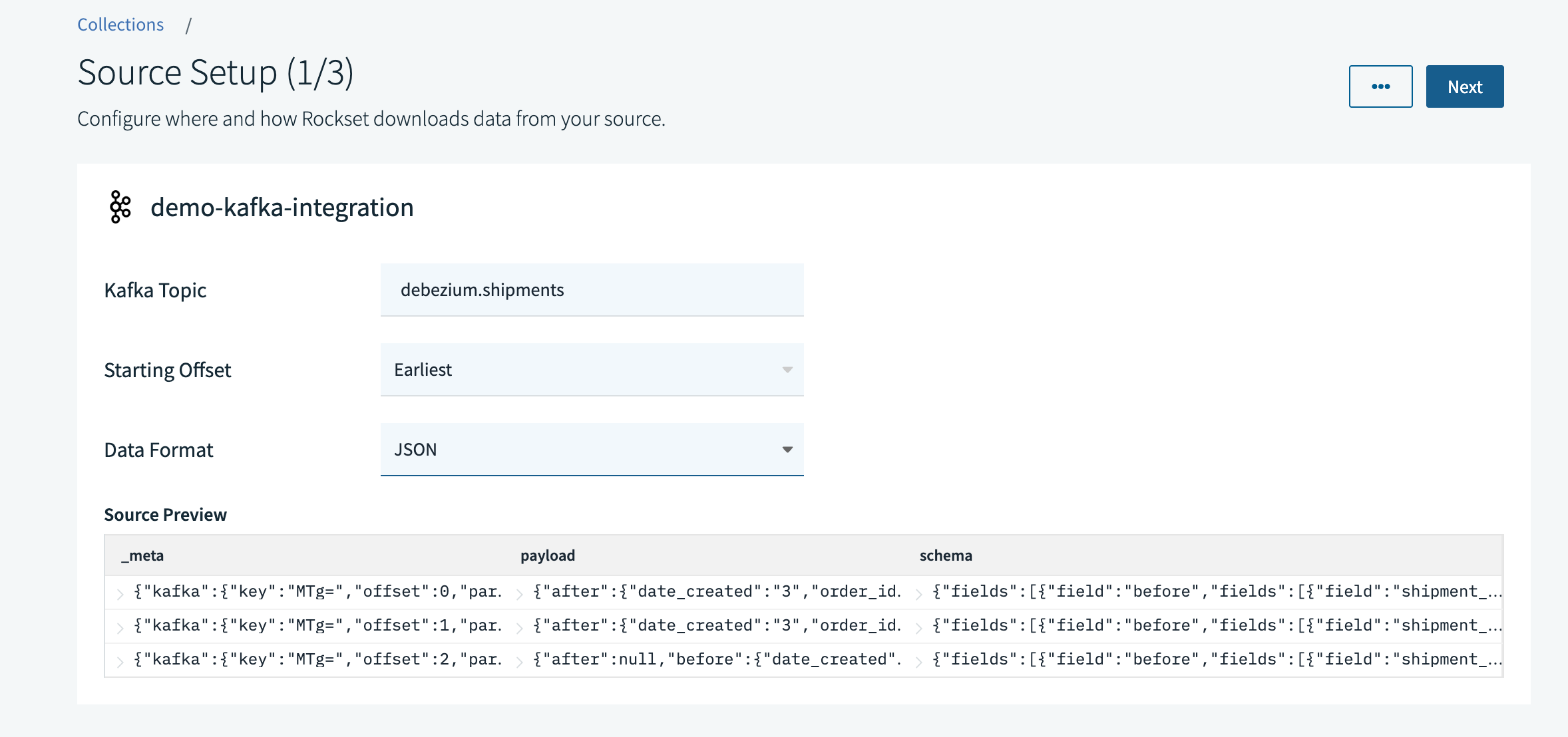
We navigate to the Rockset console to create a new collection and select Kafka. We fill out the Kafka topic name, set the offset policy to Earliest so any data we have in the topic prior to the collection creation will be ingested, and specify the format as JSON.
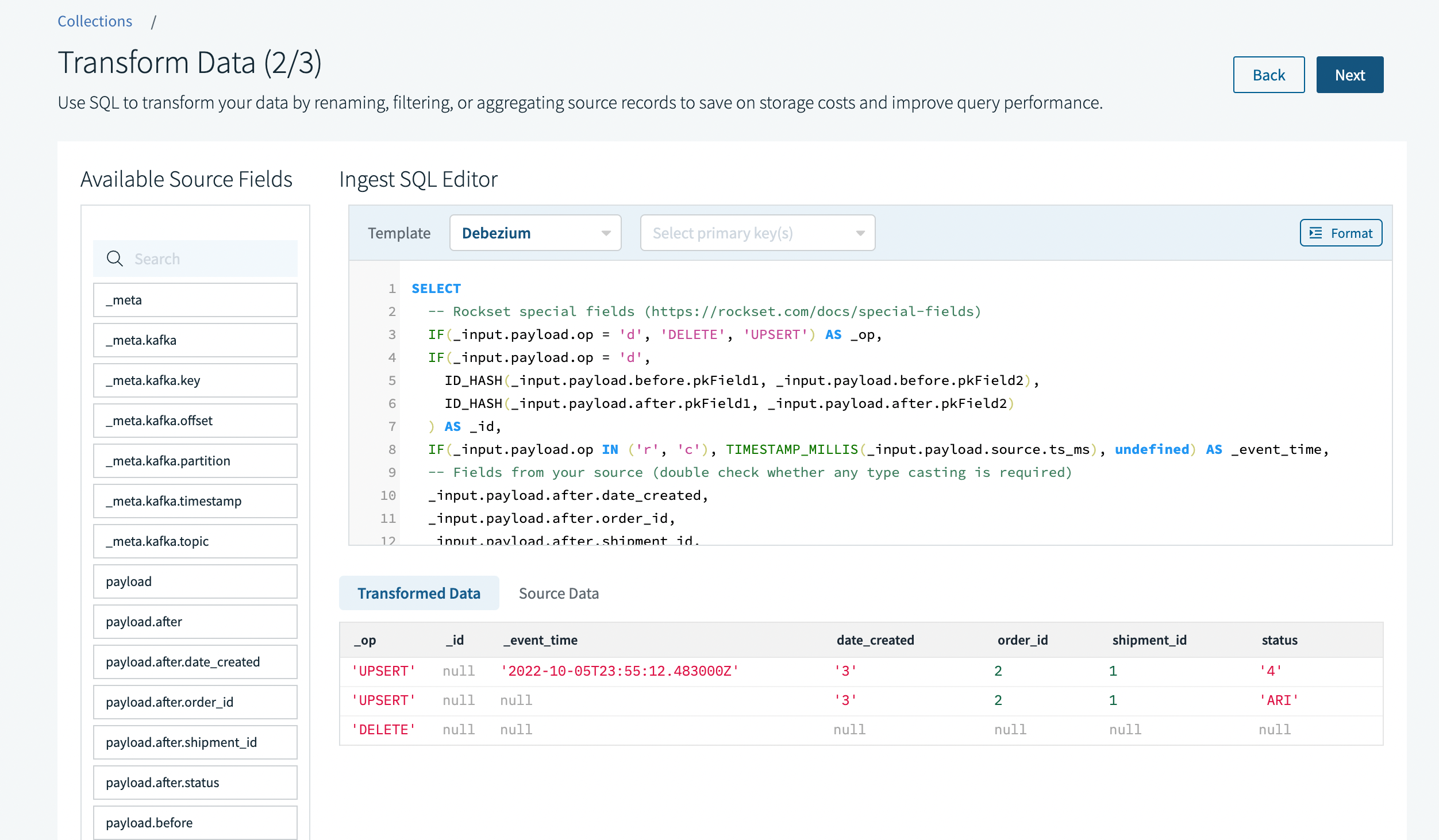
When we move to the second step of the collection creation process to set up the ingest transformation, we'll see that Rockset has already inferred the data we're bringing in is in Debezium format and has prepopulated the transformation template corresponding to Debezium.
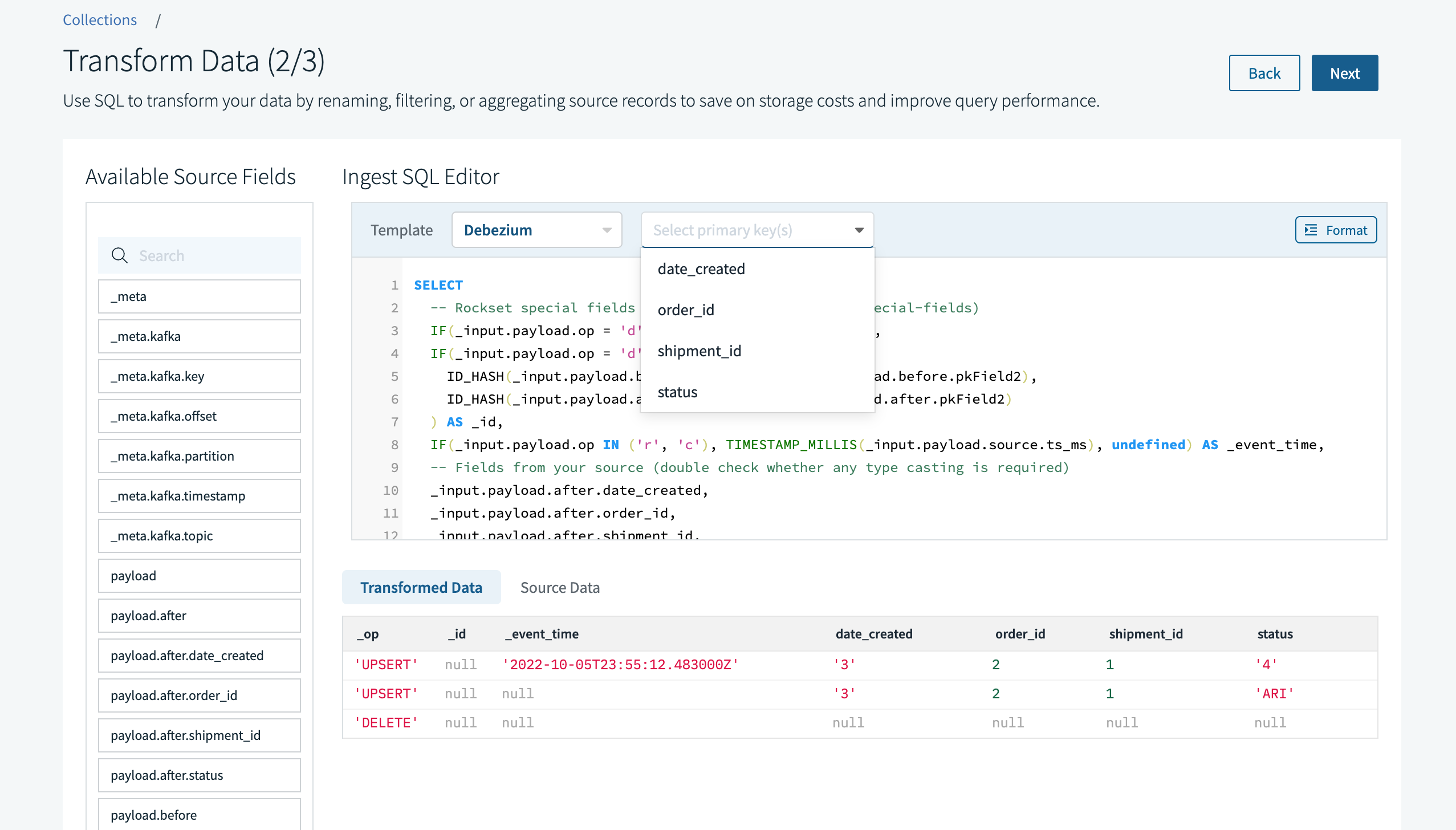
We're almost done, but Rockset doesn't know which fields correspond to the primary key in our source. So we click on the multi-select input for the primary keys and select order_id from the list of available fields Rockset has auto-detected. You can also type your own custom field name here.
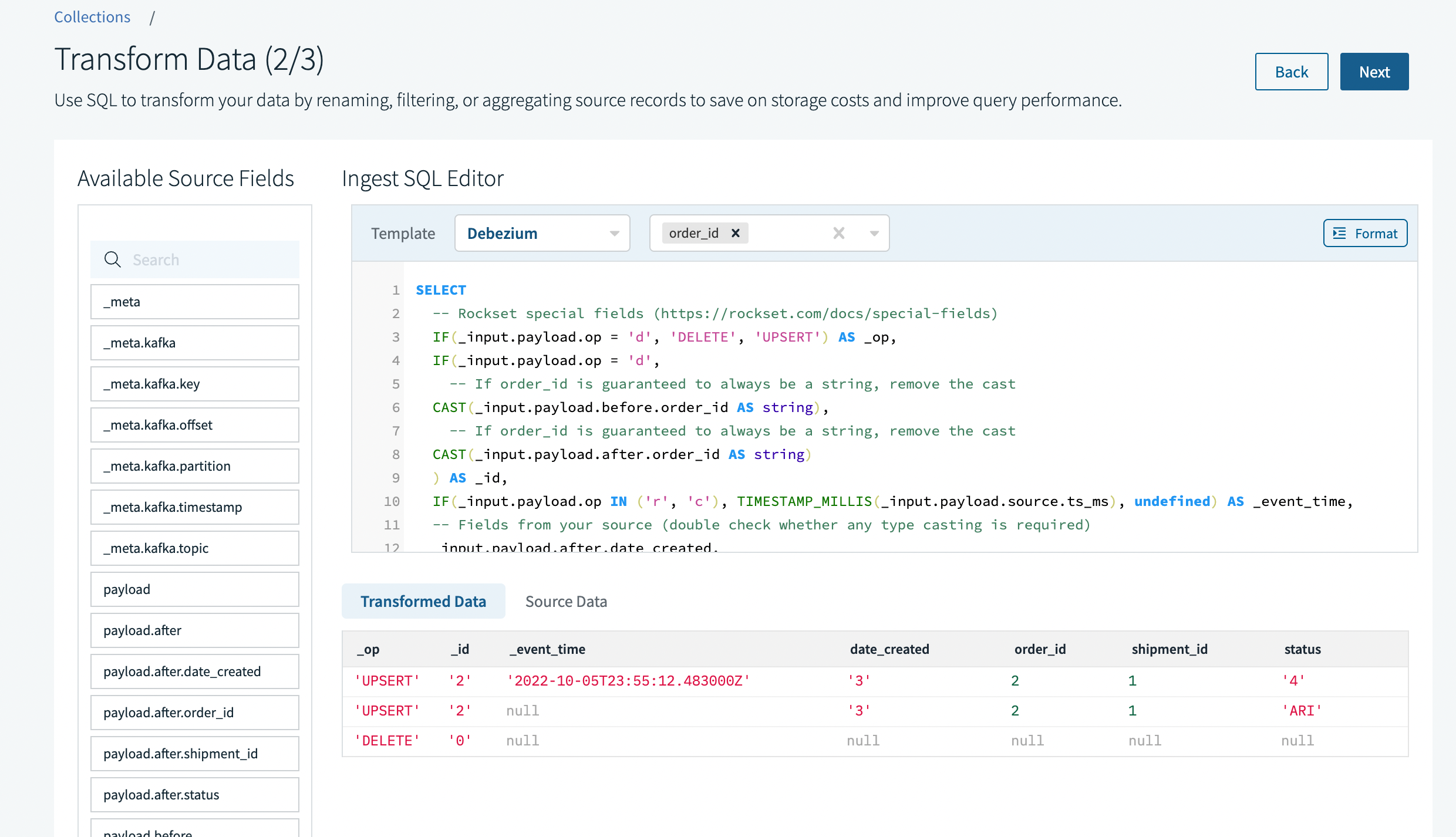
And that's it! It's a good idea to do a final inspection of the transformation to see if any additional type casting is required, if any of the projected fields may not be needed, etc. We can then complete the collection creation process and Rockset will begin ingesting the CDC records and applying the inserts, updates, and deletes accordingly.
Updated 9 months ago