
What is Vector Search?
Vector Search refers to the practice of performing a similarity search over a set of vectors or "embeddings". Embeddings are just arrays of numbers that provide a compact, meaningful representation of large, complex, and unstructured pieces of data. These embeddings are typically generated using ML models which have the ability to ingest complex unstructured data and map the data to a compressed vector form representation of fixed length.
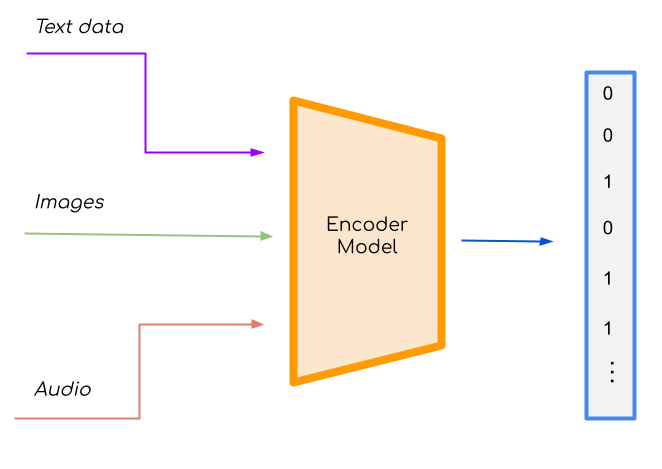
Representing complex data as compact arrays has many advantages including making storage and processing incredibly efficient. Another byproduct of working with embedding representations is that they are easily comparable with each other. You can think of vectors as points in an N-Dimensional "latent space" and as such you can calculate the distance between two vectors using standard techniques like finding the Euclidean distance. These distance functions calculate the semantic similarity of the data that was used to create the vectors and we call searching for vectors that are close to a specific vector "similarity search", otherwise known as vector search.
Vector Search has become increasing popular due to the accessibility and advancements in large language models. These language models include: GPT models from OpenAI, BERT by Google, LaMDA by Google, PaLM by Google, LLaMA by Meta AI. The embeddings generated by these models are high-dimensional and can be stored and indexed in Rockset for efficient vector search.
Check out this blog post on 5 early adoptions of Vector Search to learn more about use cases and implementation considerations.
Updated 4 months ago